AWS Services
AWS Services
The following services are commonly used for AWS solutions. Each service specifies key considerations and features per service for architecture and design.
- Serverless Services
- Serverless Benefits
- Relevant Patterns
- Deployment Types
- Networking and Content Delivery
- Compute
- Storage
- Database
- Application Integration
- Analytics
- Management & Governance
- Well-Architected Framework
- Control Tower
- Organizations
- CloudFormation
- Serverless Application Repository (SAR)
- Service Catalog
- Config
- AppConfig
- CloudWatch Logs
- CloudWatch Events (see EventBridge)
- CloudWatch Insights
- CloudWatch Metrics
- CloudWatch Dashboards
- CloudWatch Alarms
- CloudWatch Synthetics (Canaries)
- CloudTrail
- Proton
- Developer Tools
- Migration & Transfer
- Machine Learning
- Security, Identity, and Compliance
- Media Services
Serverless Services
- Route53
- Global Accelerator
- WAF
- Cognito
- CloudFront
- API Gateway
- AppSync
- Amplify
- Lambda
- DynamoDB
- S3
- SNS
- SQS
- SES
- Kinesis
- EventBridge
- Glue
- Step Functions
- Athena
- SSM Parameter Store
- Secrets Manager
- AppConfig
- AWS Config
- CloudWatch Synthetics (Canaries)
- CloudWatch Metrics and Alarms
- CloudWatch Logs
- CloudFormation
- Serverless Application Repository (SAR)
- SAM (Serverless Application Model)
- CDK
- X-Ray
Serverless Benefits
- less things to own
- less/no ops
- costs - pay-per-use
- elastic / limits scaling concerns
- deliver value quicker
- scale teams / org fit
- durability/resiliency - services built-in replication across AZs or regions
- every service has soft limits for protection
Relevant Patterns
- event sourcing
- circuit breaker - trip circuit to prevent downstream systems overload
- load shedding - prevent backlog buildup
- handle poison messages - prevent kinesis and dynamo streams from progressing
- prevent distributed transactions. e.g. lambda send job to SQS and stores status in dynamodb. break it up. lambda put job status in dynamo -> dynamo stream -> lambda send job to SQS
- strangler - migrate from monolith to serverless. e.g. DB - run RDS and dynamodb in parallel and update both for a period of time
Deployment Types
- all-at-once
- blue/green
- canary - traffic shift percentages with metrics
- linear - changing the amount of traffic split to the new version incrementally according to a percentage that is provided when configured.
Networking and Content Delivery
VPC
- virtual private cloud
- Subnets, route tables, internet gateways, elastic ips, nat gateways, network ACLs, security groups, prefix lists
ELB/ALB
Elastic Load Balancing (TCP)
ALB application load balancer — Layer 7 (HTTP/HTTPS traffic), Flexible
NLB network load balancer — Layer 4 (TLS/TCP/UDP traffic), Static IPs
CLB classic load balancer — Layer 4/7 (HTTP/TCP/SSL traffic), Legacy, Avoid
The NLB forwards requests whereas the ALB examines the contents of the HTTP request header to determine where to route the request. So, the ALB is performing content based routing.
Resource Type Hierarchy
AWS::ElasticLoadBalancingV2::LoadBalancer -> AWS::ElasticLoadBalancingV2::Listener -> [AWS::ElasticLoadBalancingV2::ListenerRule] (e.g. path based) -> AWS::ElasticLoadBalancingV2::TargetGroup -> [Instance | IP Address | Lambda | ALB]
PrivateLink / VPC Endpoint
- PrivateLink allows access to AWS services and customer provided services hosted by other AWS customers, while maintaining network traffic within the AWS network.
- connect to AWS services from VPC without going through internet
- enables you to privately connect your VPC to supported AWS services and VPC endpoint services powered by PrivateLink without requiring an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection
- gateway endpoint - S3 and DynamoDB. via VPC route table.
- gateway that you specify as a target for a route in your route table for traffic destined to a supported AWS service
- interface endpoint - all other services. via DNS resolver for VPC/subnets
- an elastic network interface with a private IP address from the IP address range of your subnet that serves as an entry point for traffic destined to a supported service
- specify subnets, security groups, IAM policy doc, enable private DNS
- VPC endpoint services
- create your own application in your VPC and configure it as an AWS PrivateLink-powered service (referred to as an endpoint service). Other AWS principals can create a connection from their VPC to your endpoint service using an interface VPC endpoint. You are the service provider, and the AWS principals that create connections to your service are service consumers.

Route 53
- managed DNS
- main service for reliability / DR
- public and private domains (hosted zones)
- route to aws services - CloudFront, API Gateway, ELB, RDS, S3 bucket, EC2, VPC Interface Endpoint
- record sets, TTL
- health checks - public endpoints or via CloudWatch metrics (e.g. for private endpoints. see
AlarmIdentifier)- can associate a health check with recordset. e.g. Route 53 failover recordset.
- load balancing via DNS
- routing policies - latency Based Routing, Geo DNS, Geoproximity, and Weighted Round Robin
- domain registration
- geo routing, geoproximity routing
- alias record type (aws specific. used for root/bare/naked domains)
- AWS Route53 — Cheat Sheet(In 2 Minutes)
Cloud Map
- name and discover your cloud resources via API or DNS
Global Accelerator
- uses the highly available and congestion-free AWS global network to direct internet traffic from your users to your applications on AWS
- fixed entry point to your applications through static IP addresses
- allocates static Anycast IP addresses that are globally unique for your application and do not change
CloudFront
- CDN
- POP / edge servers - traffic over AWS global infrastructure
- price classes
- ACM for TLS/SSL certs
- cache policies. cookie, headers, querystring, TTLs configs
- origin access identity
- origin custom headers
- signed URLs or cookies
- origin groups - primary origin and a second origin to failover to
- custom error responses - http error codes mapped to response page paths
- georestrictions
- lambda@edge - headers only requests, rewrite URLs, server-side rendering (SSR), auth, etc.
- cloudfront functions - run lightweight JavaScript code
- no network and file system access.
- max run time - run less than 1 ms.
- Where a Lambda@Edge is deployed to one of the 13 regional edge locations, Cloudfront Functions are deployed even further down and closer to the viewer at one of the 280+ edge locations
- CloudFront KeyValueStore - a low-latency, in-memory data store that can be used to store and retrieve data from within a CloudFront Function
- cache invalidations
- non GET HTTP methods support. must explicitly turn on support for PUT, POST, PATCH, etc.
- WAF association
- can point to Object Lambda Access Point
API Gateway
- REST API vs HTTP API (cost). see Choosing between HTTP APIs and REST APIs
- edge (cloudfront) and regional endpoints
- caching (memcached) (fixed cost based on time / no pay-per-use)
- API Keys
- Usage Plans / quotas
- client certificates - ensure requests to backend are from APIG
- throttles
- with WAF in front, you can set up rate-based rules to specify the number of web requests that are allowed by each client IP in a trailing, continuously updated, 5-minute period. no API Key required for this
- timeout - 29s
- request (POST) payload limits (10 MB). no response size limits. (tested with proxy integration for 200 MB video file download)
- auth - cognito, JWT, IAM (aws sigv4), custom lambda auth
- OpenAPI / Swagger specs for payload validation
- service integrations - no need for lambda glue in middle. e.g. apig -> step fns
- velocity templates (vtl) - request/response mapping
- custom domain names
- private REST API
- endpoints that are accessible only from within your VPC
- see diagram
- API Gateway private integrations
- expose your HTTP/HTTPS resources within a VPC for access by clients outside of the VPC
- VPC links for REST APIs - apig endpoint -> (NLB within VPC)
- VPC links for HTTP APIs - apig endpoint -> ([LB within VPC)
- see Understanding VPC links in Amazon API Gateway private integrations
- see diagram
- websockets
- lambda integration. point to lambda alias for deployments.
- stages
- mock integrations / responses
AppSync
- GraphQL managed service
- integrates with Amazon DynamoDB, Amazon Elasticsearch, and Amazon Lambda
- resolvers
- resolver mapping templates via velocty (vtl)
- Real-time subscriptions
- aws specific graphql schema
@directivesfor model (ddb), auth (cognito), - GraphiQL
- javascript for vtl coming (2021-03-28)
Compute
EC2
- AMI
- elastic IPs
- ASGs (launch templates)
- UserData - script to run on instance start
- EC2 metadata service
ECS
- container management service
- Fargate and EC2 launch types
- prefer ECS on Fargate over ECS on EC2. No managing ec2 cluster with fargate
- if using ECS on EC2 use Bottlerocket
- Using Bottlerocket with Amazon ECS Amazon ECS-optimized AMI variant of the Bottlerocket operating system is provided as an AMI
- task definitions
- Service - maintain a specified number of instances of a task definition
- Service load balancing - distribute traffic evenly across the tasks in your service
- Service auto scaling - via Application Auto Scaling service. CPU/memory utilization CW metrics
- EFS or EBS for persistent storage
- EFS is recommended. Can be mounted by multiple ECS tasks for parallel access
- EBS can be used but is tied to a hosting EC2 instance. Not supported on fargate.
ECR
- container registry
- concepts
- Registry - can create image repositories in your registry and store images in them
- Authorization token - client must authenticate to Amazon ECR registries as an AWS user before it can push and pull images
- Repository - contains your Docker images, Open Container Initiative (OCI) images, and OCI compatible artifacts
- Repository policy - can control access to your repositories and the images within them with repository policies
- Image - push and pull container images to your repositories
- can use them in ECS task definitions and EKS pod specifications
- ECR public
- resource-based permissions using AWS IAM
- Announcing Pull Through Cache Repositories for Amazon Elastic Container Registry
Fargate
Docs | Amazon ECS on AWS Fargate
- containers
- task definitions
- run containers without having to manage servers or clusters
- removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing.
- When you run your tasks and services with the Fargate launch type, you package your application in containers, specify the CPU and memory requirements, define networking and IAM policies, and launch the application.
- Amazon ECS tasks for Fargate can authenticate with private image registries, including Docker Hub, using basic authentication. When you enable private registry authentication, you can use private Docker images in your task definitions.
- Fargate Spot - you can run interruption tolerant Amazon ECS tasks at a discounted rate compared to the Fargate price. Fargate Spot runs tasks on spare compute capacity. When AWS needs the capacity back, your tasks will be interrupted with a two-minute warning.
- ECS Service - desired task count. allows you to run and maintain a specified number of instances of a task definition simultaneously in an Amazon ECS cluster. If any of your tasks should fail or stop for any reason, the Amazon ECS service scheduler launches another instance of your task definition to replace it in order to maintain the desired number of tasks in the service.
- optionally front with ALB
- Service autoscaling is done using the Application Auto Scaling service. See How can I configure Amazon ECS Service Auto Scaling on Fargate?
- Multi AZ by default - Fargate will look to spread Task placement across all available Availability Zones
- Deployment types - rolling update, blue/green (via CodeDeploy)
Batch
- run batch computing jobs using containers
- concepts:
- Compute Environments - set of managed or unmanaged compute resources that are used to run jobs. Fargate or EC2. specify the minimum, desired, and maximum number of vCPUs for the environment.
- Job Queues - backed by 1 or more compute envs, assign priority
- Job Definitions - cpu and memory requirements, iam role for access to other aws resources
- Jobs - things that run on fargate or ec2. shell script, a Linux executable, or a Docker container image
- Array Jobs
- run parallel jobs such as Monte Carlo simulations, parametric sweeps, or large rendering jobs.
AWS_BATCH_JOB_ARRAY_INDEXis passed to each job as an env var to represent the current index - Automated Job Retries
- Job Dependencies
- Array Jobs
- run parallel jobs such as Monte Carlo simulations, parametric sweeps, or large rendering jobs.
EKS
- managed Kubernetes
- automates the deployment, scaling, and management of containerized applications
App Runner
- Service Types
- Image-based service - container image (docker)
- Code-based service
- source code and a supported runtime (managed platforms
. e.g. python, node.js, java, .net, php, ruby, go)
- When you create an AWS App Runner service using a source code repository, AWS App Runner requires information about building and starting your service. You can set service options by using a configuration file
(
apprunner.yaml).
- When you create an AWS App Runner service using a source code repository, AWS App Runner requires information about building and starting your service. You can set service options by using a configuration file
(
- service source: source code (python, node, java, etc. provided managed runtimes) and source image (container/docker image).
- compute configurations - 0.25 vCPU (512 MB memory) and up to 4 vCPU (12 GB memory)
- public and private (VPC) support for service endpoints
- Repository provider - github, bitbucket and ECR are supported
- private service (endpoint) - enables access to App Runner services from within a VPC.
- Enabling Private endpoint for incoming traffic
- AWS::AppRunner::VpcIngressConnection
- associate your App Runner service to an Amazon VPC endpoint
- AWS::AppRunner::VpcIngressConnection.DomainName
. build URL with
!Sub https://${AppRunnerService1VpcIngressConnection.DomainName}
- AWS::AppRunner::VpcIngressConnection.DomainName
. build URL with
- create AWS::EC2::VPCEndpoint
with
ServiceName: !Sub "com.amazonaws.${AWS::Region}.apprunner.requests" - see KarlDeux/arps/template.yaml for full example.
- service access VPC resources - e.g. app access to RDS database running in VPC
- VPC Connector - enables associate your service with a VPC by creating a VPC endpoint
- Enabling VPC access for outgoing traffic
- AWS::AppRunner::VpcConnector
LightSail
- Virtual servers, storage, databases, and networking for a low, predictable price.
- backed by EC2, but easier to use
- similar to DigitalOcean
Elastic Beanstalk
- PaaS with language runtime + docker containers
- heroku-like
- App Runner is the recommended service for new applications
Lambda
- synchronous, asynchronous, poll based/stream processing (poll based is sync. via event-source mappings), respoonse streaming
- memory - single knob for memory and CPU (between 128 MB and 10,240 MB, and up to 6 vCPUs)
- Lambda function URLs
- DLQ
- lambda destinations (only for async invokes)
- reserved concurrency - concurrency allocated for a specific function. e.g. i always want fn X to be able to run 10 lambda invokes concurrently
- provisioned concurrency - pre-warmed lambda instances / no cold starts. good for latency sensitive needs
- can optionally use auto scaling to adjust on based on metrics and/or schedule.
- will spill over to on-demand scaling (lambda default)
- Provisioned Concurrency comes out of your regional concurrency limit
- concurrent executions (throttles) - 1000 per account
- timeout - 15min
- set code timeouts based on remaining invocation time provided in context
- burst concurrency - 500 - 3000
- burst - 500 new instances / min
- poll based options (kinesis, dynamodb, SQS)
- on-failure destination (SNS or SQS)
- retry attempts
- max age of record - use to implement load shedding (prioritize newer messages)
- split batch on error
- concurrent batches per shard
- APIG -> lambda
- ALB -> lambda
- service integrations - Using AWS Lambda with other services - AWS Lambda
- lambda private endpoints - access lambda from VPC without going over internet
- Lambda Extensions - executables in /opt/extensions that conform to the Lambda Extensions API
- Container Images
- Runtime interface clients
- runtime interface client in your container image manages the interaction between Lambda and your function code
- Lambda provides an open source runtime interface client for each of the supported Lambda runtimes. e.g. node.js, python, etc.
- Lambda Runtime Interface Emulator
- allows customers to locally test their Lambda function packaged as a container image
- web-server that converts HTTP requests to JSON events and maintains functional parity with the Lambda Runtime API
- max image size: 10 GB
- Runtime interface clients
- Lambda Wrapper Scripts | Modifying the runtime environment - customize the runtime startup behavior of your Lambda function. e.g. set env vars, add/update parameters.
- AWS Lambda Operator Guide
- Lambda runtime management controls
- visibility into which patch version of a runtime your function is using and when runtime updates are applied
- can optionally synchronize runtime updates with function deployments
- roll back your function to an earlier runtime version.
- example - lambda CloudWatch log line
Runtime Version: python:3.9.v14 Runtime Version ARN: arn:aws:lambda:eu-south-1::runtime:7b620fc2e66107a1046b140b9d320295811af3ad5d4c6a011fad1fa65127e9e6I
- example - lambda CloudWatch log line
- Introducing AWS Lambda response streaming
- send responses larger than Lambda’s 6 MB response payload limit up to a soft limit of 20 MB.
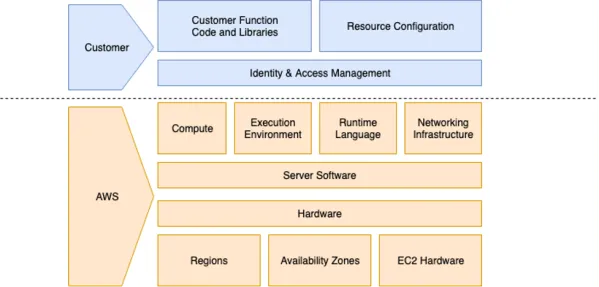
Shared responsibility model for AWS Lambda
Lambda@Edge
- feature of Amazon CloudFront that lets you run code closer to users of your application, which improves performance and reduces latency
EC2 Image Builder
automate the creation, management, and deployment of customized, secure, and up-to-date “golden” server images that are pre-installed and pre-configured with software and settings to meet specific IT standards.
- automate the creation of EC2 AMI and docker images
Storage
S3
- object/blob storage with strong read-after-write consistency
- versioned buckets
- presigned URLs for private content (download or upload)
- S3 batch operations
- S3 select
- Query via Athena
- batch operations - perform operation on list of objects specified in manifest. e.g. lambda, copy, etc.
- storage classes - Standard, Standard-IA, Intelligent-Tiering, One Zone-IA, Glacier Instant Retrieval, Glacier Flexible Retrieval, Glacier Deep Archive
- lifecycle rules - moving between storage tiers for cost savings
- replication - cross-region, same-region
- access points - managing data access at scale, access points are unique hostnames, enforce distinct permissions and network controls for any request made through the access point, scale to many applications accessing bucket with own set of permissions.
- S3 Object Lock - write-once-read-many (WORM) model. retention periods and legal holds.
- static website hosting
- Multi-Region Access Points
- addresses pain point- Managing access to this shared bucket requires a single bucket policy that controls access for dozens to hundreds of applications with different permission levels
- Multi-Region access points
- S3 event notifications - notification destinations are SNS, SQS, lambda
- Use Amazon S3 Event Notifications with Amazon EventBridge
- S3 object lambda
- process data retrieved from S3 with lambda before returning it to an application. lambda calls
writeGetObjectResponseto send modified object contents back toGETrequest. Create S3 Access Point, then Object Lambda Access Point. - Mountpoint for Amazon S3
Glacier
- low cost/long-term object/blob storage
EFS (Elastic File System)
- elastic file system for Linux-based workloads for use with AWS Cloud services and on-premises resources.
- can mount as NFS v4
- e.g. shared file system. many EC2 instances can mount same efs file system.
- can mount to lambda local filesystem
FSx
- File System X, where X means your choice + any workload
- NetApp ONTAP, Windows File Server, Lustre, ZFS
FSx for Windows File Server
- fully managed native windows file system
- SMB, NTFS, AD integration
FSx for Lustre
- fully managed native lustre file system - the open-source, parallel file system
- designed to support any Linux workload and is POSIX-compliant
- sub-millisecond latencies, millions of IOPS, and throughput of as much as hundreds of gigabytes per second.
- workload types - HPC, ML, media processing and transcoding, big data
- deployment options
- Scratch File Systems - shorter-term processing of data and for temporary storage. In the event that a file server fails, data does not persist and is not replicated.
- Persistent File Systems - file servers remain highly available and data is automatically replicated in the same Availability Zone (AZ) as the file system. The data volumes connected to the file servers are replicated separately from the file system they are attached to
- mount lustre file system to S3 bucket
- Choosing an Amazon FSx File System
FSx for ONTAP
- NFS, SMB and iSCSI storage powered by NetApp
- HA across multi-AZs
- automatic data tiering to S3, and instant data cloning
Storage Gateway
- NFS or SMB interface to S3, FSx, volume/tape gateways
- compute runs on once of following: ec2, kvm, VMware, Hyper-V, or appliance
- if SMB, need to Configuring Microsoft Active Directory access
- VPC support. network traffic between compute and AWS Service goes over VPC endpoint
- VPC endpoint enabled, all VPC endpoint communication from your gateway to AWS services occurs through the public service endpoint using your VPC in AWS
- Creating a VPC endpoint for Storage Gateway
Amazon File Cache
- temporary, high-performance storage for data in on-premises file systems, or in file systems or object stores on AWS
- link the cache to multiple NFS file systems—including on-premises and in-cloud file systems—or Amazon Simple Storage Service (S3) buckets, providing a unified view of and fast access to your data spanning on-premises and multiple AWS Regions
- create cache by specifying: Cache name, Cache storage capacity (Set this to a value of 1.2 TiB, 2.4 TiB, or increments of 2.4 TiB), Throughput capacity, VPC, Security Groups, Subnets
- create Data repository associations (DRAs) - linking your cache to Amazon S3 or NFS data repositories
- Data repository path (e.g.
s3://my-bucket/my-prefix/), cache path (e.g./ns1/subdir1)
- Data repository path (e.g.
- mount NFSv3 or S3.
sudo mount -t lustre -o relatime,flock cache_dns_name@tcp:/mountname /mnt - supports ec2, ecs, eks
- write to cache support. need to manually export changes to sources
- To export changes from the cache, use HSM commands. When you export a file or directory using HSM commands, your cache exports only data files and metadata that were created or modified since the last export.
- see https://docs.aws.amazon.com/fsx/latest/FileCacheGuide/exporting-files-hsm.html
sudo lfs hsm_archive path/to/export/file sudo lfs hsm_state path/to/export/file
- access your cache from a Linux instance, first install the open-source Lustre client.
EBS
- block level storage volumes for use with EC2 instances. EBS volumes behave like raw, unformatted block devices
AWS Transfer
- SFTP to S3
- enables the transfer of files directly into and out of S3 using SFTP
- public facing and w/in VPC
- File Transfer Workflows (AWS::Transfer::Workflow ) – MFTW is a fully managed, serverless File Transfer Workflow service that makes it easy to set up, run, automate, and monitor the processing of uploaded files.
AWS Backup
- centralize and automate data protection across AWS services
- configure backup policies and monitor activity for your AWS resources in one place
- backup and restore for: EC2 instances, S3 data, EBS volumes, DynamoDB tables, RDS database instances, Aurora clusters, EFS and FSx FSs, Storage Gateway volumes, DocumentDB clusters, Neptune clusters
- concepts
- Backup Vault
- Backup Plans
- Backup Selection - e.g. backup resources having tag(s)
- Backup Plans
- Backup Vault
Database
DynamoDB
- concepts - tables, items, queries, scans, indexes
- global tables - for resilient active-active architectures
- DAX - DynamoDB Accelerator - in memory cache in front
- GSI (Global Secondary Indexes), LSI (Local Secondary Indexes)
- transactions
- throttles
- point-in-time recovery (PITR)
- streams - 24hr data retention. poison messages (retry until success - can cause backlog)
- partition key - distribute data among nodes to minimize hot partitions
- TTL - can the data be removed automatically
- parallelization factor for DDB streams processed by lambda
- single table designs
- fine grained item (
dynamodb:LeadingKeys) and attribute level IAM (dynamodb:Attributes). enables multi-tenant isolation. - Amazon DynamoDB Encryption Client
- PartiQL - A SQL-Compatible Query Language for Amazon DynamoDB - Amazon DynamoDB
- dynamodb table export to s3
- dynamodb table import from s3
- DynamoDB Standard-IA table class
you will save up to 60 percent in storage costs as compared to using the DynamoDB Standard table class. However, DynamoDB reads and writes for this new table class are priced higher than the Standard tables
- DynamoDB zero-ETL integration with Amazon OpenSearch
- Amazon DynamoDB zero-ETL integration with Amazon Redshift
DocumentDB (MongoDB compatibility)
RDS
- Aurora, PostgreSQL, MySql, MariaDB, Oracle, SQL Sever
- DB Instance (contains 1 or more dbs), Instance Classes (compute+memory), Instance Storage
- HA Multi-AZ
- Database Activity Streams - supported for Oracle and SQL Server
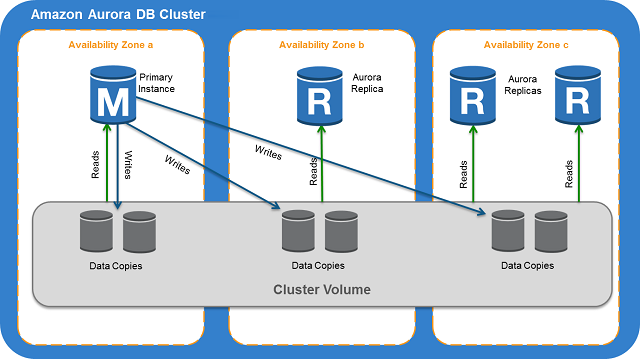
Amazon Aurora
- fully managed relational database engine that’s compatible with MySQL and PostgreSQL
- compute and storage are separate. underlying storage grows automatically as needed. An Aurora cluster volume can grow to a maximum size of 128 tebibytes (TiB)
- HA - data remains safe even if some or all of the DB instances in the cluster become unavailable
- Aurora DB cluster consists of one or more DB instances and a cluster volume that manages the data for those DB instances
- When data is written to the primary DB instance, Aurora synchronously replicates the data across Availability Zones to six storage nodes associated with your cluster volume. Doing so provides data redundancy, eliminates I/O freezes, and minimizes latency spikes during system backups.
- cluster endpoint - a connection string that stays the same even when a failover promotes a new primary instance. cluster endpoint always represents the current primary instance in the cluster.
- DB Instance Types
- Primary DB instance - Supports read and write operations, and performs all of the data modifications to the cluster volume. Each Aurora DB cluster has one primary DB instance.
- Aurora Replica - Connects to the same storage volume as the primary DB instance and supports only read operations. Each Aurora DB cluster can have up to 15 Aurora Replicas in addition to the primary DB instance.
- Amazon Aurora connection management
- primary instance handles all data definition language (DDL) and data manipulation language (DML) statements.
- Up to 15 Aurora Replicas handle read-only query traffic
- Types of Aurora endpoints
- Cluster endpoint - read/write/DDL/DML (e.g.
mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com:3306) - Reader endpoint - provides load-balancing support for read-only connections to the DB cluster. (e.g.
mydbcluster.cluster-ro-123456789012.us-east-1.rds.amazonaws.com:3306) - Custom endpoint - represents a set of DB instances that you choose. When you connect to the endpoint, Aurora performs load balancing and chooses one of the instances in the group to handle the connection. (e.g.
myendpoint.cluster-custom-123456789012.us-east-1.rds.amazonaws.com:3306) - Instance endpoint - connects to a specific DB instance within an Aurora cluster. (e.g.
mydbinstance.123456789012.us-east-1.rds.amazonaws.com:3306)
- Cluster endpoint - read/write/DDL/DML (e.g.
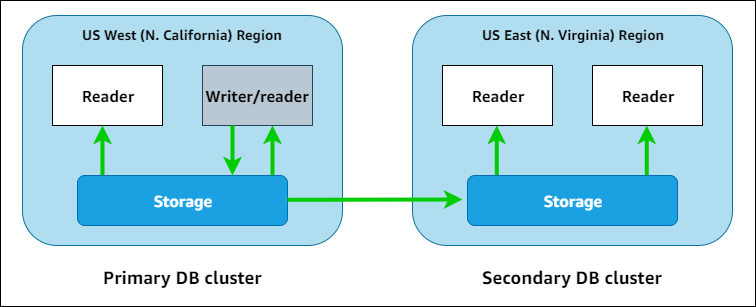
- Amazon Aurora global databases
Aurora Serverless
- Using the Data API for Aurora Serverless v1 - http API, no long lived connections
Redshift
- managed data warehouse service.
- postgres foundation
- RA3 instances - Scale compute and storage independently for fast query performance and lower costs
- UDFs - lambda backed,
- Redshift Data API - http based (no JDBC or ODBC). async so can retrieve results later. query results stored for 24 hrs
- redshift spectrum - SQL queries on data stored in S3
- Kinesis Data Streaming ingestion - eliminates the need to stage data in S3 before ingesting it into Redshift
- zero-ETL integrations - RDS -> Redshift
- Amazon DynamoDB zero-ETL integration with Amazon Redshift
Redshift Serverless
- automatically provisions data warehouse capacity and intelligently scales the underlying resources
- concepts
- Namespace is a collection of database objects and users
- Workgroup is a collection of compute resources
- RPUs - Redshift Processing Units (RPUs). RPUs are resources used to handle workloads.
- costs - billed RPU hours on a per-second basis. no queries are running, not billed for compute capacity. charged for Redshift managed storage, based on the amount of data stored.
ElastiCache
- managed redis and memcached
ElasticSearch / OpenSearch
- cluster
- kibana - integrated with IAM
- IAM for granular es api operations
- automated time-based data deletion via index lifecycle policies
Amazon OpenSearch Serverless
- removes need to configure, manage, or scale OpenSearch clusters (called provisioned OpenSearch domains, which you manually manage capacity for)
- collection - group of indices representing a specific workload or use case. two collection types - time series and search
- capacity is managed for you. you create a collection, then you query and index data using the same OpenSearch APIs as before
- Serverless compute capacity is measured in OpenSearch Compute Units (OCUs). Each OCU is a combination of 6 GiB of memory and corresponding virtual CPU (vCPU), as well as data transfer to S3
- decouples compute and storage. separates the indexing (ingest) components from the search (query) components, with S3 as the primary data storage for indexes. can scale search and index functions independently of each other and independently of the indexed data in S3.
- costs - charged for the following components:
- data ingestion compute
- search and query compute
- storage retained in S3
- billed for a minimum of 4 OCUs for the first collection in your account
- CloudFormation Resource Types | OpenSearch Serverless
Neptune
- graph database. query languages Apache TinkerPop Gremlin and SPARQL (RDF)
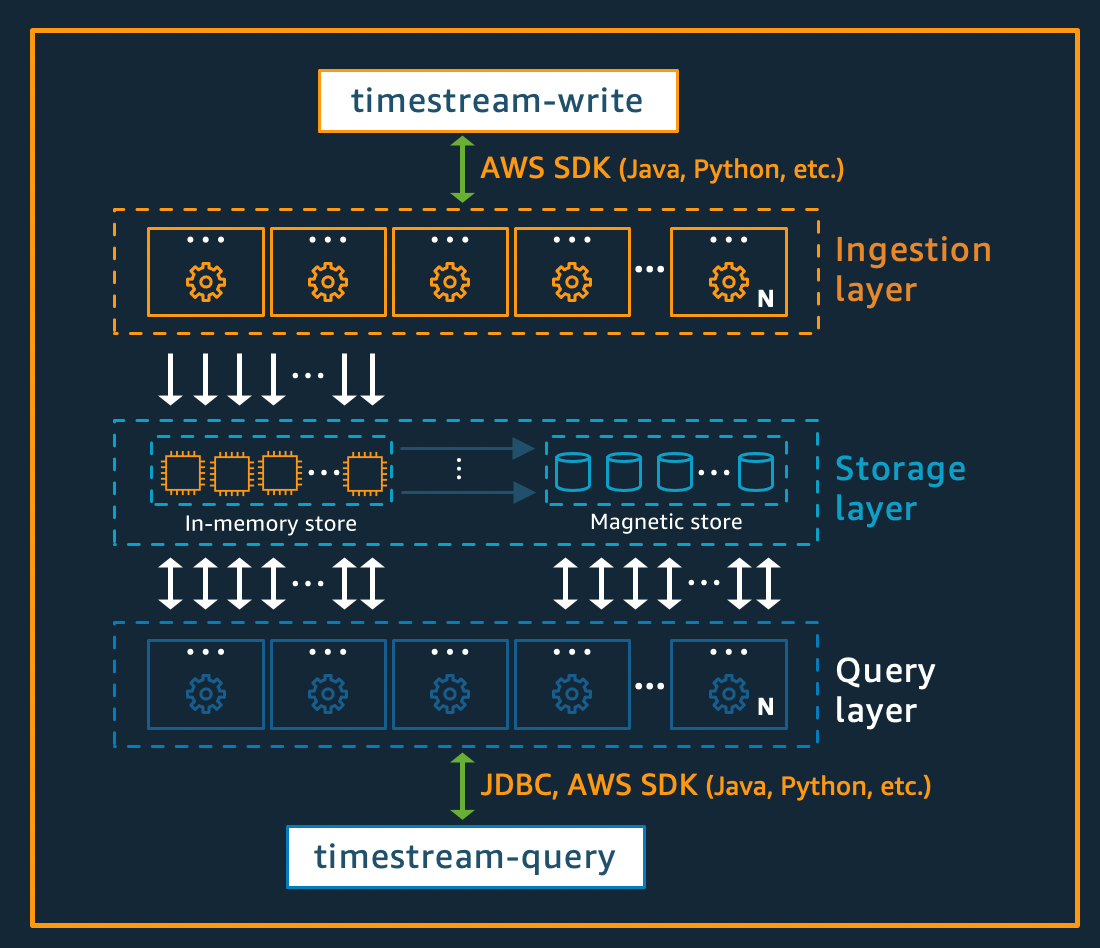
Timestream
- time series database
- use SQL to query
- Concepts
- Time series - A sequence of one or more data points (or records) recorded over a time interval.
- Record - A single data point in a time series
- Multi-measure records - store multiple measures in a single table row, instead of storing one measure per table row
- Dimension - An attribute that describes the meta-data of a time series. A dimension consists of a dimension name and a dimension value.
- Measure - The actual value being measured by the record. Examples are the stock price, the CPU or memory utilization, and the temperature or humidity reading
- Timestamp - Indicates when a measure was collected for a given record
- Table - A container for a set of related time series.
- Database - A top level container for tables.
- Scheduled Query - Timestream periodically and automatically runs these queries and reliably writes the query results into a separate table. serverless and fully managed
- Query string - query to run
- Schedule expression - when your scheduled query instances are run. using a cron expression
- Target configuration - map the result of a scheduled query into the destination table where the results of this scheduled query will be stored.
- Notification configuration - receive a notification for every such query run on an SNS topic that you configure when you create a scheduled query.
- fully decoupled data ingestion, storage, and query architecture where each component can scale independent of other components
- storage tiering, with a memory store for recent data and a magnetic store for historical data
- InfluxDB, Prometheus, Riak

Cloud Directory
- cloud-native directory that can store hundreds of millions of application-specific objects with multiple relationships and schemas
SSM Parameter Store
- Systems Manager Parameter Store provides secure, hierarchical storage for configuration data management and secrets management
Application Integration
AppFlow
- managed integration (ETL) service
- securely transfer data between SaaS applications (Salesforce, Marketo, Slack, etc.), and AWS services (S3, Redshift, EventBridge, etc.)
- concepts - flow, source, destination, flow trigger (on demand, event, schedule), map fields from source to destination (formula transforms, value validations), filters (determine records to transfer)
- Flow notifications - flow start|complete|deactivated events sent to CloudWatch Events/EventBridge (
"source": "aws.appflow") - security
- encryption at rest - connection data stored in secrets manger using AWS managed or Customer managed CMK
- Encryption in Transit (TLS 1.2) - choose either an AWS managed CMK or a customer managed CMK. When executing a flow, Amazon AppFlow stores data temporarily in an intermediate S3 bucket and encrypts it using this key. This intermediate bucket is deleted after 24 hours, using a bucket lifecycle policy.
- Actions defined by Amazon AppFlow
- AppFlow integrations - built-in integrations
- Custom Connector SDK (python or java) - source data from any system
Step Functions
- Standard Workflows (max duration: 1 yr)
- exactly-once model
- Express Workflows (max duration: 5 min)
- need to be idempotent / at-least-once model, where an execution could potentially run more than once
- States - Task, Choice, Wait, Pass, Parallel, Map, Succeed, Fail
- Activities - enables you to have a task in your state machine where the work is performed by a worker that can be hosted anywhere.
- start other
[sub]workflows - error handling and Retrying after an error
- Input/Output Processing
- InputPath to select a portion of the state input
- Parameters field to create a collection of key-value pairs that are passed as input
- ResultSelector field to manipulate a state’s result before
ResultPathis applied - OutputPath enables you to select a portion of the state output to pass to the next state
- orchestration with many built-in integrations to aws services
- Step Functions AWS SDK Service Integrations
- full execution event history for a given execution
- Intrinsic functions - use these instead of creating lambdas to do logic.
- Logging using CloudWatch Logs
- Logging Step Functions Using AWS CloudTrail
- CloudWatch Metrics
- EventBridge Events - Execution started, succeeded, failed, timed out, aborted
- X-Ray tracing support
- saga pattern for rollback
- parallel map opportunities - run tasks in parallel
- service integrations
- request/response, run a job (
.sync), callback with task token (.waitForTaskToken) - JSONPath expressions
- Data flow simulator
- Step Functions Workflow Studio - visual designer for state machines
- VPC Endpoint support
- Step Functions Local - downloadable version of Step Functions that lets you develop and test applications using a version of Step Functions running in your own development environment.
SNS
if not doing “sizable” fan-out, see if EventBridge meets the need (more features around archiving, replay, retries)
- pub/sub
- message filtering with subscription
- push notifications
- standard topic
- at least once delivery
- best effort ordering - ensure downstream consumers are idempotent
- FIFO topic
- strict ordering
- Strict deduplication: Duplicate messages aren’t delivered.
- Deduplication happens within a 5-minute interval, from the message publish time.
- FIFO Topic Message Archiving and Replay - e.g. replay topic messages to SQS
- fan out
- subscription filters
- destination types
- SQS
- lambda
- http/s
- mobile push notifications
- SMS messages
- DLQ configuration
- KMS encryption
SQS
- managed message queuing service
- batch size - batch fails as unit
- visibility timeout - set to 6x lambda timeout
- message retention period
- delivery delay - max 15min
- types - standard vs FIFO
- standard - at least once delivery. need to ensure idempotent
- FIFO - strict ordering. exactly-once processing
- alarm on queue depth
- KMS encryption
- DLQ for redrive for messages that can’t be delivered to target SQS queue
- partial batch response - Reporting batch item failures when used with lamdba
SES
- send or receive emails
- verify domain (DNS txt) and/or email addresses (confirmation email) - verify that you own the email address or domain that you plan to send from
- understand Service quotas
- max message size - 10 MB per message (after base64 encoding).
- sending identity - domain or an email address
- send emails via SMTP or API (AWS CLI, AWS SDK )
- connect to a URL that provides an endpoint for the Amazon SES API or SMTP interface (e.g. email-smtp.us-east-1.amazonaws.com:587)
- DKIM support - DKIM works by adding a digital signature to the headers of an email message. This signature can then be validated against a public cryptographic key that is located in the organization’s DNS record
- SPF support - SPF establishes a method for receiving mail servers to verify that incoming email from a domain was sent from a host authorized by that domain’s administrators
- IAM to control user access to email sending (e.g.
ses:SendEmail) - Configuration sets - groups of rules that you can apply to the emails you send using Amazon SES. can publish email sending events to CWL, Firehose, SNS
- Event types - Send, Reject, Delivery, Bounce, Complaint, Click Open Rendering Failure
- store inbound emails in S3
- trigger lambdas based on inbound emails
- publish your email sending events to CWLs or kinesis firehose
- Sending personalized email via email templates. templates contain placeholder values. based on Handlebars template system
- list management
- customers can manage their own mailing lists, known as contact lists.
- can create topics, associate topic preferences to a contact and specify
OPT_[IN|OUT]for the topic.
- Global Suppression List
- includes a global suppression list. When any Amazon SES customer sends an email that results in a hard bounce, Amazon SES adds the email address that produced the bounce to a global suppression list. The global suppression list is global in the sense that it applies to all Amazon SES customers. In other words, if a different customer attempts to send an email to an address that’s on the global suppression list, Amazon SES accepts the message, but doesn’t send it, because the email address is suppressed.
- enabled by default for all Amazon SES accounts. You can’t disable it.
- reputation dashboard to track bounce and complaint rates
- Dedicated IP Addresses
- IP pool management – If you lease dedicated IP addresses to use with Amazon SES, you can create groups of these addresses, called dedicated IP pools. You can then associate these dedicated IP pools with configuration sets
- SES sandbox - all new accounts.
- only send mail to verified email addresses and domains
- only send mail from verified email addresses and domains
- send a maximum of 200 messages per 24-hour period
- send a maximum of 1 message per second
- need to request production access to move out of sandbox
- VPC endpoint support - see New – Amazon Simple Email Service (SES) for VPC Endpoints
EventBridge
- pub/sub with many built-in integrations
- integrate with external SaaS or any custom application
- bus-to-bus routing within same account + region, x-account, and x-region.
- dlq for eb rules. if fails to deliver to target, goes in sqs queue
- e.g. can log all events in account including CloudTrail to CloudWatch Log Group
- put events - 2400 requests per second per region
- AWS service rule targets
- at-least-once event delivery to targets (ensure idempotent behavior)
- no ordering guarantees
- schema registry - helps with managing and versioning event schemas for evolution. Codegen code for handling events in various languages. can auto discover schemas by observing events on the bus. based on json schema
- invocation quota - 4500 requests per second per region (invocation is an event matching a rule and being sent on to the rule’s targets)
- DLQ
- EventBridge resource policies
- archive and replay events
- IAM - resource-based and identity-based policies. owner of EB resources (bus, rules, etc.) is an AWS root account.
- supports sending and recieving events across accounts
- API destinations - integrate with services outside of AWS using REST API calls. e.g. send events to a third-party service that doesn’t have a built-in integration with EventBridge
- SaaS Partner Integrations
- X-Ray Tracing support
- EventBridge Scheduler - can schedule one-time or recurrently tens of millions of tasks across many AWS services
- Amazon EventBridge Pipes
- create point-to-point integrations between event producers and consumers with optional transform, filter and enrich steps
- high-level concepts: sources , source event filter , transform and enrich , targets
Kinesis
- collect, process, and analyze real-time, streaming data
- kafka alternative
- partition key
- shard count
- Kinesis Data Streams On-Demand Mode - charged per gigabyte of data written, read, and stored in the stream, in a pay-per-throughput fashion
- ordering guaranteed for messages per shard
- dynamic partitioning - continuously partition streaming data in Kinesis Data Firehose using keys within data like “customer_id” or “transaction_id” and deliver data grouped by these keys into corresponding Amazon Simple Storage Service (Amazon S3) prefixes
- lambda - lambda polls per shard
- batch size
- batch window
- parallelization factor
- Concurrent batches per shard – Process multiple batches from the same shard concurrently.
- enhanced fan-out via AWS::Kinesis::StreamConsumer. each consumer gets 2 MiB per second for every shard you subscribe to. can subscribe a max of 5 consumers per stream.
- Starting position - Latest, Trim horizon, At timestamp
- On-failure destination
- Retry attempts
- Maximum age of record – The maximum age of a record that Lambda sends to your function.
- Split batch on error
- poison messages (retry until success - can cause backlog)
- KMS
- aggregate multiple records into one while staying under size limits to increase throughput. see https://github.com/awslabs/kinesis-aggregation
- no autoscaling around shards. requires management/ops. consider SQS first as there’s less to manage and see if it can meet the need
AWS Application Composer
Analytics
Kinesis Data Analytics
Process and analyze streaming data using SQL or Java.
- two application types are supported
- SQL Applications
- AWS specific
- concepts - application, input steam -> application code (SQL statements) -> output stream
- time based windows. tumbling windows.
- pump
- Apache Flink Applications
- OSS standard for streaming
- you can use Java, Scala, or SQL to process and analyze streaming data
- use DataStream API and Table API
- SQL Applications
- AWS specific
Pinpoint
usage, customer, and engagement analytics
EMR
hadoop, spark, and friends
- Amazon EMR Serverless
- part of the job specification, you can provide the minimum and maximum number of concurrent workers, and the vCPU, memory, and storage for each worker
- charged for aggregate vCPU, memory, and storage resources used from the time workers start executing till the time they terminate, rounded up to the nearest second with a one-minute minimum.
Data Pipelines
data processing workloads
AWS Data Pipeline, you can regularly access your data where it’s stored, transform and process it at scale, and efficiently transfer the results to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR.
Glue
- catalog / metadata (hive metadata catalog)
- crawlers autodiscover schema
- data sources - S3, RDS, JDBC, dynamodb, mongodb, documentdb
- data targets - S3, RDS, JDBC, mongodb, documentdb
- jobs
- job types - Spark, Streaming ETL (kinesis, kafka via spark structured streaming (micro batches)), and Python shell
- python shell job start-up time - 7-30 secs (based on usage observations)
- languages - [py]spark and scala
- concepts - Data Catalog, Classifier, Connection, Crawler, Database, Table, Dynamic Frame (extend spark RDD), Job, Transform, Trigger (time based or event)
- Auto Scaling for AWS Glue
- AWS Glue interactive sessions - run locally via jupyter notebook. replaces Glue Dev endpoint. serverless with no infrastructure to manage. You can start interactive sessions very quickly. Interactive sessions have a 1-minute billing minimum with cost-control features. This reduces the cost of developing data preparation applications.
- Developing using a Docker image - AWS Glue hosts Docker images on Docker Hub to set up your development environment with additional utilities.
- glue notebook (Jupyter/Zeppelin) - interactive development and testing of your ETL scripts on a development endpoint
- partitions
- AWS Data Wrangler - excellent integration library to use with glue via python shell jobs
- Starting an AWS Glue Workflow with an Amazon EventBridge Event - trigger a workflow/job via EventBridge
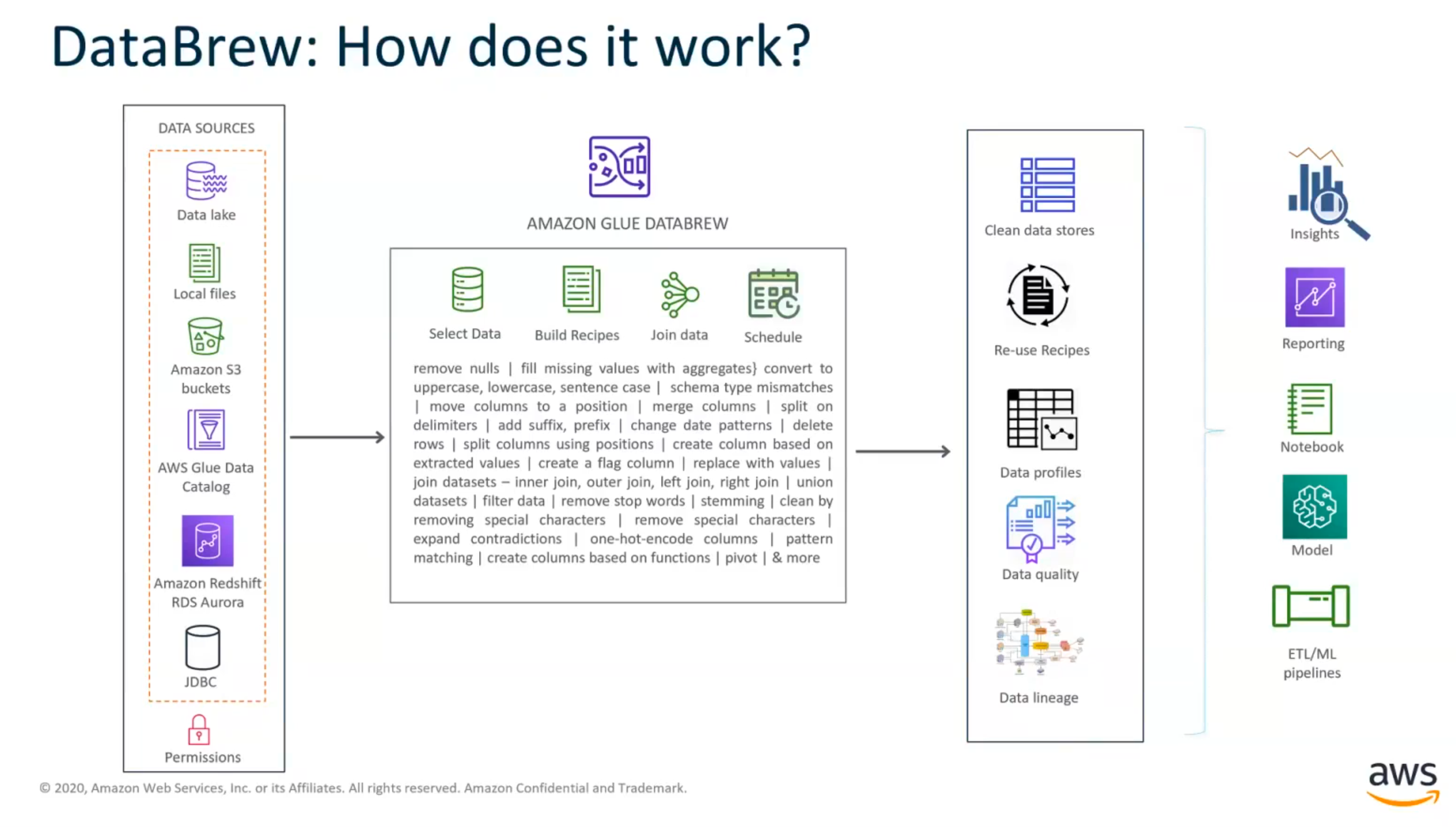
Glue DataBrew
- visual data preparation service
- extract, clean, normalize, transform, combine, data at scale
- target audience: non-technical Data Analyst
- serverless. pay for what you use
- concepts
- datasets
- recipes - steps to apply/take on dataset
- job - recipe + dataset run
- project - visual workspace for working with data interactively. can apply changes and visually see the results in UI. you specify a sampling of the data to work with.
Athena
- serverless querying of S3 data
- federated query - run SQL queries across data stored in relational, non-relational, object, and custom data sources.
- CTAS - create table as select
- query S3 data in place. pay per query / data accessed.
- integrated with glue catalog
- Presto is underlying tech
- Connecting to Amazon Athena with ODBC and JDBC Drivers
- QuickSight Integration
QuickSight
Lake Formation
Management & Governance
Well-Architected Framework
- describes the key concepts, design principles, and architectural best practices for designing and running workloads in the cloud
- 6 pillars - Operational Excellence, Security, Reliability, Performance, Cost Optimization, Sustainability
- Well-Architected Tool - provides guidance by answer questions
- Lens - serverless, analytics, ML, SaaS, etc.
Control Tower
set up and govern a new, secure multi-account AWS environment. builders can provision new AWS accounts in a few clicks, while you have peace of mind knowing your accounts conform to your company-wide policies
Organizations
- account management service that lets you consolidate multiple AWS accounts into an organization that you create and centrally manage.
CloudFormation
- declarative provisioning of AWS infrastructure/resource
- parameters, mappings, conditionals
- intrinsic functions
- change sets
- nested stacks
- stack drift
- stacksets - deploy stack to multiple regions. provide the accounts and regions to deploy to. For DR, active-active, etc.
- max resources declared in stack (500)
- custom resources - backed by lambda
- macros - lambda performs the template processing / transform
- modules - package resource configurations for inclusion across stack templates, in a transparent, manageable, and repeatable way
- CloudFormation Registry
- IaC generator - generate a CloudFormation template using resources provisioned in your account that are not already managed by CloudFormation
Serverless Application Repository (SAR)
enables teams, organizations, and individual developers to find, deploy, publish, share, store, and easily assemble serverless architectures
- any cfn can be used for SAR app
- iam for access to SAR app
Service Catalog
- create and manage catalogs of IT services that are approved for use on AWS
- concepts:
- products are cloudformation templates
- portfolio is collection of products
- access to portfolios is via IAM users, groups, roles
- IT administrator creates products and portfolios and grants access
- End user accesses products and deploys them
- approved self-service products from Solution Factory
- e.g. Oracle RDS DB with all security, tags, etc. in place
- e.g. static web site. S3 + CloudFormation + WAF + ACM (certificate) + Route 53 (hosted zone, domain)
- Service Actions - enable end users to perform operational tasks, troubleshoot issues, run approved commands, or request permissions in AWS Service Catalog via SSM docs.
Config
- monitor, notify, quarantine, remediate based on resource changes.
- RDK - rule development kit. Config triggers lambda on resource changes.
- AWS Config is a service that enables you to assess, audit, and evaluate the configurations of your AWS resources. Config continuously monitors and records your AWS resource configurations and allows you to automate the evaluation of recorded configurations against desired configurations.
- define rules that get evaluated when any change is made (e.g. resource provisioned)
- conformance - collection of Config rules and remediation actions. portable. can be applied across multiple accounts and regions
- there are aws managed rules that are part of the service and you can define custom ones via lambda
AppConfig
- feature flags, Update applications without interruptions, Control deployment of changes across your application
- a capability of AWS Systems Manager, to create, manage, and quickly deploy application configurations. AppConfig supports controlled deployments to applications of any size and includes built-in validation checks and monitoring. You can use AppConfig with applications hosted on EC2 instances, AWS Lambda, containers, mobile applications, or IoT devices.
- JSON Schema Validators - ensure that new or updated configuration settings conform to the best practices required by your application
- e.g. a JSON doc with application configuration can be sourced from S3, parameter store
CloudWatch Logs
- centralize the logs from all of your systems, applications, and AWS services that you use, in a single, highly scalable service
- concepts - log groups, log streams
- subscriptions - real-time feed of log events from CloudWatch Logs (Kinesis
[stream|firehose], elasticsearch, Lambda) - Creating Metrics From Log Events Using Filters
- encrypt with KMS
CloudWatch Events (see EventBridge )
- cron triggers
CloudWatch Insights
- query log groups
- CWL Query Syntax
CloudWatch Metrics
- time series data
- metric - time-ordered set of data points that are published to CloudWatch
- concepts - namespace, dimensions (name/value pairs), units (Bytes, Seconds, Count, and Percent), time stamp, resolution (granularity)
- statistics - sum, max, min, average, sample count, percentile (pNN) (metric data aggregations over specified periods of time)
- metrics retention
- Creating Metrics From Log Events Using Filters
- Embedded Metric Format - generate metrics from structured (json) log messages
- CloudWatch Metric Streams - metrics are delivered to a Kinesis Data Firehose stream
CloudWatch Dashboards
- CloudWatch Dashboards - for Visualizations
- Dashboard Custom Widgets - dashboard widget that can call any AWS Lambda function with custom parameters. It then displays the returned HTML or JSON.
- CloudWatch Dashboard Sharing - Share a single dashboard and designate specific email addresses, Share a single dashboard publicly, so that anyone who has the link can view the dashboard, Share all the CloudWatch dashboards in your account and specify a third-party single sign-on (SSO)
CloudWatch Alarms
- notify via email, SNS topics
- create a CloudWatch alarm that watches a single CloudWatch metric or the result of a math expression based on CloudWatch metrics
- An alarm watches a single metric over a specified time period, and performs one or more specified actions, based on the value of the metric relative to a threshold over time. The action is a notification sent to an Amazon SNS topic or an Auto Scaling policy. You can also add alarms to dashboards.
- composite alarms
- Alarm States - OK, ALARM, INSUFFICIENT_DATA (missing data points)
- EventBridge integration - CloudWatch sends events to Amazon EventBridge whenever a CloudWatch alarm changes alarm state.
CloudWatch Synthetics (Canaries)
- supports monitoring your REST APIs, URLs, and website content every minute, 24x7, and alerts you when your application endpoints don’t behave as expected.
- Node.js or python based. bundles in Puppeteer + Chromium to the runtime
- trigger types - cron (1 min smallest freq), run once
- can run in VPC
- can also used in any workloads requiring general browser automation
- creates several CloudWatch metrics in
CloudWatchSyntheticsnamespace - EventBridge support. See monitoring canary events with Amazon EventBridge
- CloudFormation support via
AWS::Synthetics::Canary
create canaries, configurable scripts that run on a schedule, to monitor your endpoints and APIs. Canaries follow the same routes and perform the same actions as a customer, which makes it possible for you to continually verify your customer experience even when you don’t have any customer traffic on your applications. By using canaries, you can discover issues before your customers do.
CloudTrail
- logs all recording AWS API and Management Console actions to S3
- can query via Athena
Proton
- self-serve for platform enabling teams
- enables the standardization of cross cutting concerns for microservices based solutions (composition of many microservices).
- e.g. the following is needed for each microservice and should be consistent/aligned with standards and best practices: compute, DNS, load balancing, code deployment pipeline, monitoring and alarms
- similar goals as Netflix’s Spinnaker
k8s ecosystem
Developer Tools
AWS Application Composer
- visual designer that you can use to build your serverless applications from multiple AWS services
Cloud9
- cloud/browser based compute environment and IDE.
- dev machine (ec2 amzn linux) in the cloud with browser based IDE and terminal
CodeCommit
- fully-managed source control service that hosts secure Git-based repositories
CodeBuild
- managed build service
- provides prepackaged build environments
- continuous integration service that compiles source code, runs tests, and produces software packages
- like Jenkins, Travis, CircleCI
- concepts - build project - environment (linux/windows, container image to use, etc.),
buildspec.yml- phases, env vars, artifacts- can be used to run ad-hoc workloads over lambda when need to run longer than 15 min
CodeDeploy
- automates software deployments to a variety of compute services such as Amazon EC2, AWS Fargate, AWS Lambda, and your on-premises servers
CodePipeline
- continuous delivery service that helps you automate your release pipelines
- orchestrates CodeBuild and CodeDeploy
- sources: github, CodeCommit, S3
CodeArtifact
- fully managed software artifact repository service that makes it easy for organizations of any size to securely store, publish, and share packages used in their software development process
- artifactory competitor
X-Ray
- distributed tracing
- instrument code
- similar to zipkin, jaeger
AWS CLI
~/.aws/[config|credentials]--generate-cli-skeleton- e.g.aws codebuild start-build --generate-cli-skeleton > build.json->aws codebuild start-build --cli-input-json file://start-build.json
Amplify
- CLI to provision resources (Auth (cogntio), API (API Gateway), GraphQL (AppSync), Storage (S3, DynamoDB))
- client-side javascript/typescript, iOS, Android libraries and UI components
- Amplify Console. CI/CD static site hosting.
SAM (Serverless Application Model)
- higher-level cfn resource types (transformed via cfn macro on backend)
- SAM CLI
- local development features via docker (apig endpoint
CDK
- express resources using general purpose programming languages (ts/js/python/java/C#)
- constructs - cfn (L1), CDK (L2), pattern/solution (L3)
- synth to cfn
- cloud assemblies - cfn + source code, docker images, assets (s3)
- aspects - ability to visit each node/resource in stack and apply changes
- Application -> Stacks -> Constructs
- Runtime context
[tf|k8s]CDKsnc- jsii - core/foundational tech for multi-language/polyglot support. bind any language to underlying typescript implementation.
- CDK pipelines for CI/CD
- CDK Migrate - cloudformation to CDK
AWS SDKs
- built in retries, timeouts
- can configure timeouts (e.g.
AWS.config.update({maxRetries: 2, httpOptions: { timeout: 2 * 1000, connectTimeout: 3 * 1000, },}))
Migration & Transfer
AWS DataSync
copy data between NFS, SMB, S3, EFS, FSx, HDFS
concepts
transfer types
- Data transfer between self-managed storage and AWS
- need to install an agent that can access self-managed storage
- Data transfer between AWS storage services
- no need to install an agent
- Data transfer between self-managed storage and AWS
agent
- VM that runs the sync software.
- can run on EC2 or hypervisors (VMware ESXi, KVM, and Microsoft Hyper-V hypervisors)
scheduled transfers
Data transfer between self-managed storage and AWS

Data transfer between AWS storage services

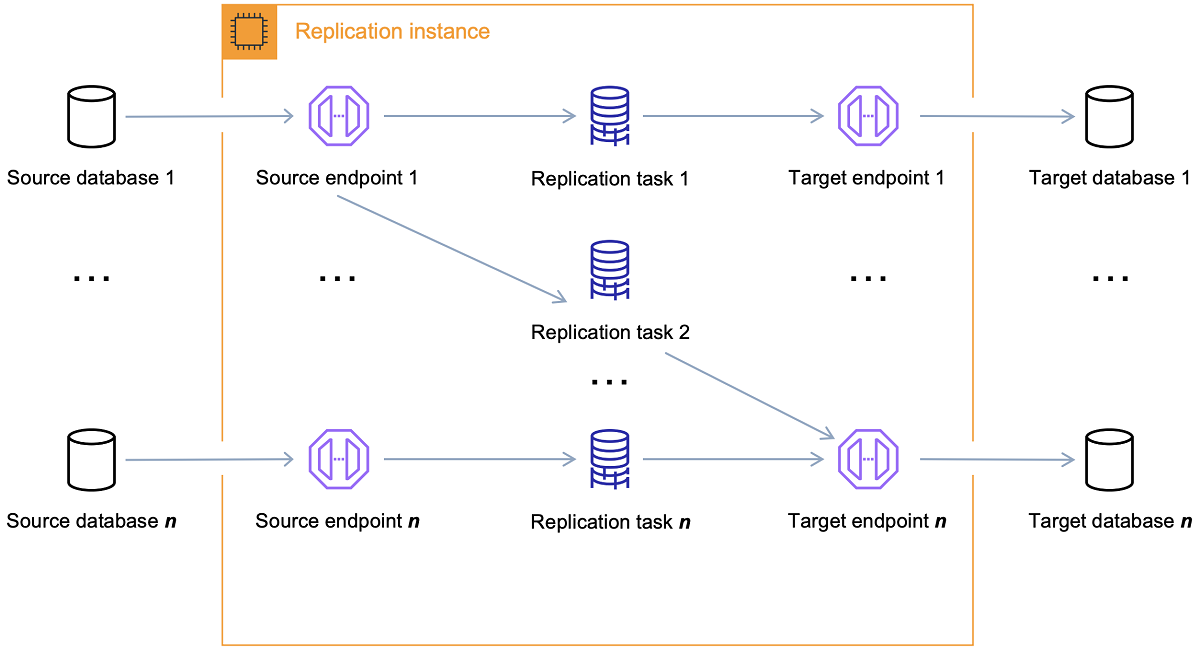
AWS DMS (Database Migration Service)
- migrate RDBS, data warehouses, nosql dbs, etc. in cloud, between combos of cloud and on-prem
- it’s a server (EC2) in the cloud that runs replication software (replication engine). DMS replication instance types
- create source and target connections
- schedule task on server to move data
- pay-as-you-go model
- data at rest is encrypted
- SSL / TLS encrypts data in -flight
- HA with multi-AZ deployment
- can provision DMS resources using CloudFormation.
- migration types: one-time, ongoing replication (CDC)
- AWS DMS doesn’t perform schema or code conversion
- you can use the AWS Schema Conversion Tool (AWS SCT)
- create endpoints to access source or target data store.
- endpoint properties
- Endpoint type – Source or target.
- Engine type – Type of database engine, such as Oracle or PostgreSQL..
- Server name – Server name or IP address that AWS DMS can reach.
- Port – Port number used for database server connections.
- Encryption – Secure Socket Layer (SSL) mode, if SSL is used to encrypt the connection.
- Credentials – User name and password for an account with the required access rights.
- At a high level, when using AWS DMS you do the following:
- Create a replication server.
- Create source and target endpoints that have connection information about your data stores.
- Create one or more migration tasks to migrate data between the source and target data stores.
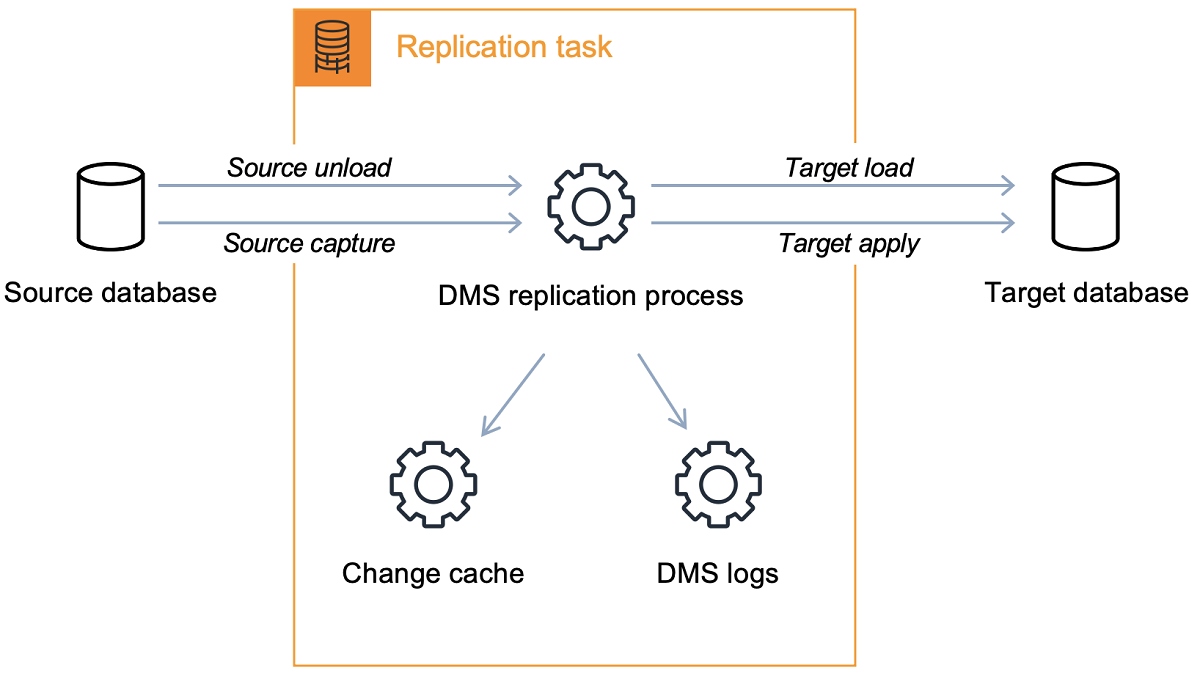
- A replication task can consist of three major phases:
- The full load of existing data
- The application of cached changes
- Ongoing replication
At the start of the ongoing replication phase, a backlog of transactions generally causes some lag between the source and target databases. The migration eventually reaches a steady state after working through this backlog of transactions.
If your migration is heterogeneous (between two databases that use different engine types), you can use the AWS Schema Conversion Tool (AWS SCT) to generate a complete target schema for you.
- Depending on the Amazon EC2 instance class you select, your replication instance comes with either 50 GB or 100 GB of data storage
- public and private replication instances
- You use a private instance when both source and target databases are in the same network that is connected to the replication instance’s VPC. The network can be connected to the VPC by using a VPN, AWS Direct Connect, or VPC peering.
- DMS Replication Process

- Replication
Machine Learning
SageMaker
- build, train, and deploy machine learning models
- provides a suite of built-in algorithms (via docker containers). provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment
- prebuilt containers for common machine learning frameworks—such as Tensorflow, Pytorch, and MxNet
- customer can bring own custom containers (bring-your-own-algorithms and frameworks)
- To train a model in SageMaker, you create a training job that includes
- S3 location with training data
- Specify ML Compute instances managed by SageMaker
- S3 location to store output of job
- ECR path to where training code is
- model serving endpoints (inference) (SageMaker Hosting Services ). your endpoint config specifys instance type, number of instances, etc.
- jupyter notebooks
- SageMaker notebook instance is a machine learning (ML) compute instance running the Jupyter Notebook App
- Amazon SageMaker Python SDK
- Serverless Inference - ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts. Serverless endpoints automatically launch compute resources and scale them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies
- Asynchronous inference - ideal for requests with large payload sizes (up to 1GB), long processing times (up to 15 minutes), and near real-time latency requirements. Asynchronous Inference enables you to save on costs by autoscaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests.
- SageMaker Model Building Pipelines
- build pipelines using the SageMaker Python SDK
- can run locally via SageMaker Pipelines local mode
Comprehend
- NLP (natural language processing)
- By utilizing NLP, you can extract important phrases, sentiment, syntax, key entities such as brand, date, location, person, etc., and the language of the text
- find insights and relationships in text
- use case e.g.: gauge whether customer sentiment is positive, neutral, negative, or mixed based on the feedback you receive via support calls, emails, social media, and other online channels
Polly
- text-to-speech (TTS)
- supports MP3, Vorbis, and raw PCM audio stream formats
- Neural Text-to-Speech (NTTS) voices
Rekognition
- API to analyze any image or video file
- identify the objects, people, text, scenes, and activities, as well as detect any inappropriate content.
Textract
- extracts text and data from scanned documents
- supports PNG, JPEG, and PDF formats. For synchronous APIs, you can submit images either as an S3 object or as a byte array. For asynchronous APIs, you can submit S3 objects
Translate
- neural machine translation service for translating text to and from English across a breadth of supported languages
Transcribe
- audio to text
- transcription services for your audio files. It uses advanced machine learning technologies to recognize spoken words and transcribe them into text.
Forecast
- managed deep learning service for time-series forecasting. By providing Amazon Forecast with historical time-series data, you can predict future points in the series.
Personalize
- create individualized recommendations for customers using their applications
- e.g. use cases
- Personalized recommendations
- Similar items
- Personalized re-ranking i.e. re-rank a list of items for a user
- Personalized promotions/notifications
Lex
- conversational interfaces into any application using voice and text. Amazon Lex provides the advanced deep learning functionalities of automatic speech recognition (ASR) for converting speech to text, and natural language understanding (NLU) to recognize the intent of the text
- chat bots
Kendra
- intelligent search service (ML powered)
- concepts - index, documents (html, pdf, word, ppt, txt), data sources (S3, confluence, OneDrive, etc.), query
- point indexer to files in S3
- pre-built faceted search UI component (web based)
- supports custom data sources . e.g. salesforce attachments data source
- can create custom document attributes
- developer and enterprise editions
Security, Identity, and Compliance
IAM
- terms - Resources, Identities, Entities, Principals (person or application), Actions
- authentication, authorization
- actions and operations on resources
- policy docs - AWS managed policies, Customer managed policies, Inline policies
- Policy Types
- Identity-based (e.g. users, groups, roles)
- Resource-based policies (e.g. bucket policy, IAM role trust policy, lambda permissions, sns topic policy, sqs queue policy, kms key policy, vpc endpoint policy)
- Permissions boundaries
- Organizations SCPs
- Session policies - via assume role or federated user. Session policies limit permissions for a created session, but do not grant permissions.
- STS - temp security credentials
- assume role
- identity providers/federation - Federated users and roles (via OIDC, SAML2)
- Attribute-based access control (ABAC) - defines permissions based on attributes (tags)
- permission boundaries
- sigv4 requests
- account root user
- MFA
- IAM Access Analyzer - validate policies, generate policies (based on CT logs, role or user, and timeframe)
Cognito
- UserPool
- IdentityPool - exchange UserPool.Identity for temporary IAM credentials
- unauthenticated and authenticated roles
- Built-in IdP Providers - amazon, google, twitter, facebook.
- Federation - OIDC, SAML
- API Gateway authorizer
- provided login UIs
Secrets Manager
WAF
- web application firewall
- associate with followng resource types: ALB, CloudFront Distribution, API Gateway REST API, AppSync GraphQL API
- concepts
- Web ACLs - contain rules and/or rule groups
- Rules - contains a statement that defines the inspection criteria, and an action to take if a web request meets the criteria
- Rules groups - group of rules for easier management
AWS::SecretsManager::SecretTargetAttachment- link between a Secrets Manager secret and the associated database by adding the database connection information to the secret JSON
Certificate Manager (ACM)
- provision, manage, and deploy public and private Secure Sockets Layer/Transport Layer Security (SSL/TLS) certificates for use with AWS services and your internal connected resources.
KMS
- key management service - AWS KMS concepts
- symmetric, asymmetric (pki)
- kye types: Customer managed key (CMK), AWS managed key, AWS owned key
- key policy determines principals that can use (identity and service)
- envelope encryption - key to gen data key, data key used to encrypt plaintext, key to encrypt data key, encrypted data + encrypted data key stored
- aws encryption sdk and cli
Directory Service
- provides multiple ways to set up and run Amazon Cloud Directory, Amazon Cognito, and Microsoft AD with other AWS services. Amazon Cloud Directory provides a highly scalable directory store for your application’s multihierarchical data. Amazon Cognito helps you create a directory store that authenticates your users either through your own user pools or through federated identity providers. AWS Directory Service for Microsoft Active Directory (Enterprise Edition), also known as Microsoft AD, enables your directory-aware workloads and AWS resources to use a managed Active Directory in the AWS Cloud.
Media Services
Amazon Interactive Video Service
Amazon Interactive Video Service (Amazon IVS) is a managed live streaming solution that is quick and easy to set up, and ideal for creating interactive video experiences. Send your live streams to Amazon IVS using standard streaming software like Open Broadcaster Software (OBS) and the service does everything you need to make low-latency live video available to any viewer around the world, letting you focus on building interactive experiences alongside the live video.