AWS Well-Architected
deep dive on all things AWS Well-Architected
Key Points
- consistent pre-launch review process against AWS best practices
- helps you understand the pros and cons of decisions you make while building systems
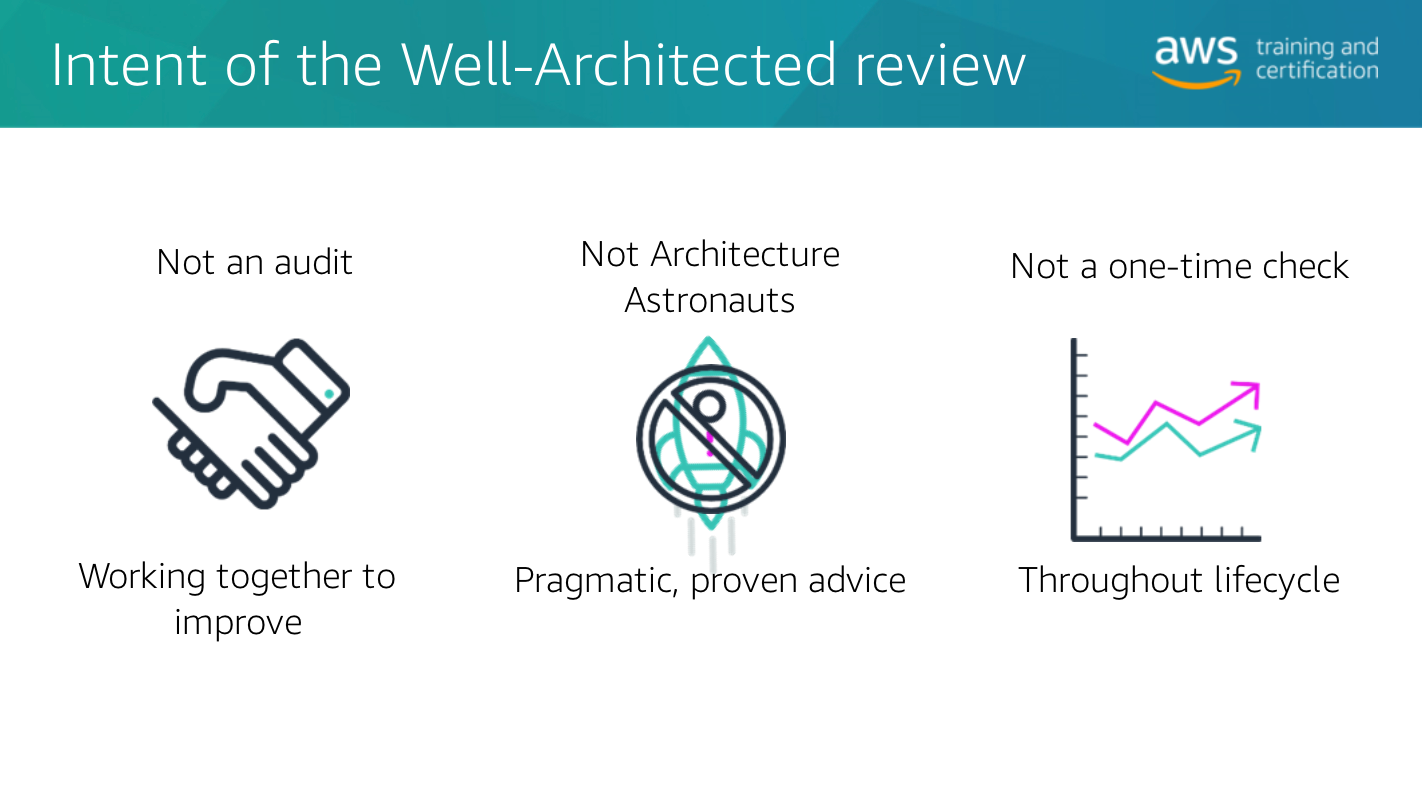
- review process is a conversation and not an audit. working together to improve. practical advice.
- goal is not to have “perfect” architecture from the start. identify areas for improvement and choose a couple that delivery the most value
- AWS does not provide prescriptive guidance on how to perform the review. WA tool is the closest.
- concepts: Pillars -> Design Principles -> Questions
- enables: learn -> measure -> improve iterative cycle
- input: answer questions, output: improvement plan (PDF reports)
- learning / education - can be used as standalone tool solely for learning what the best practices are
- milestone - record the state of a workload for given point in time. e.g. original design, design review, v1, v2
Use Cases
- learning best practices for the cloud
- technology governance
- portfolio management - inventory of workloads, historical decisions made, risks, highlights where to invest
Well-Architected Framework
The AWS Well-Architected Framework helps you to design and operate a reliable, secure, efficient, and cost-efficient systems on AWS. It also helps you constantly measure your architecture against best practices and provides you an opportunity to improve your architecture.
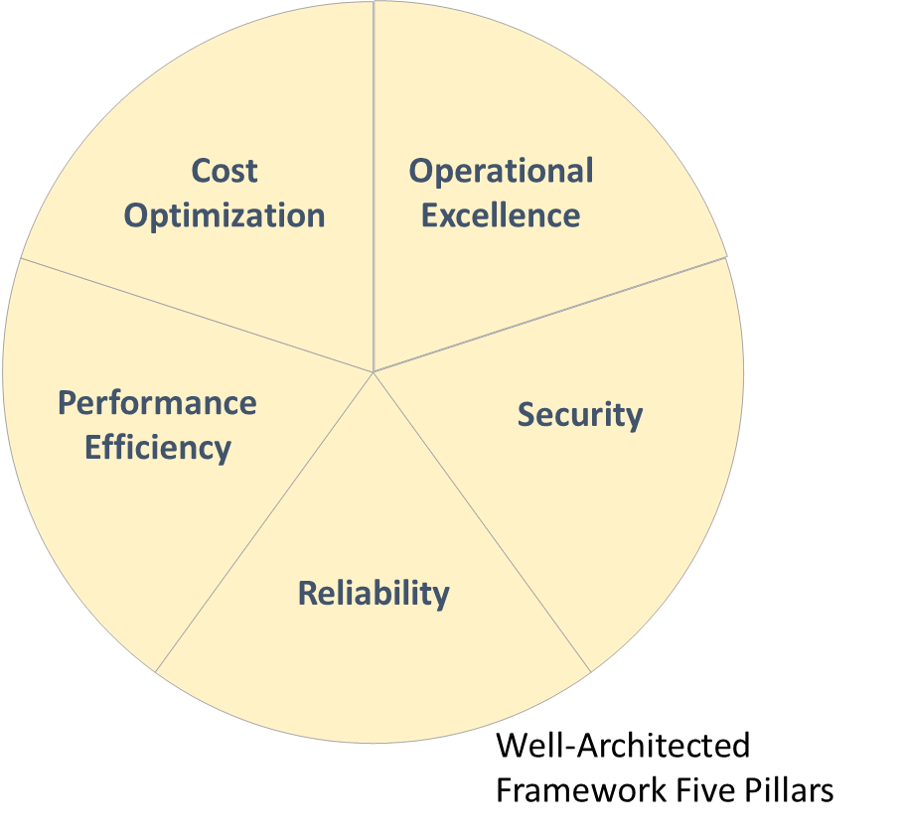
5 Pillars
- Operational Excellence
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
Design Principles
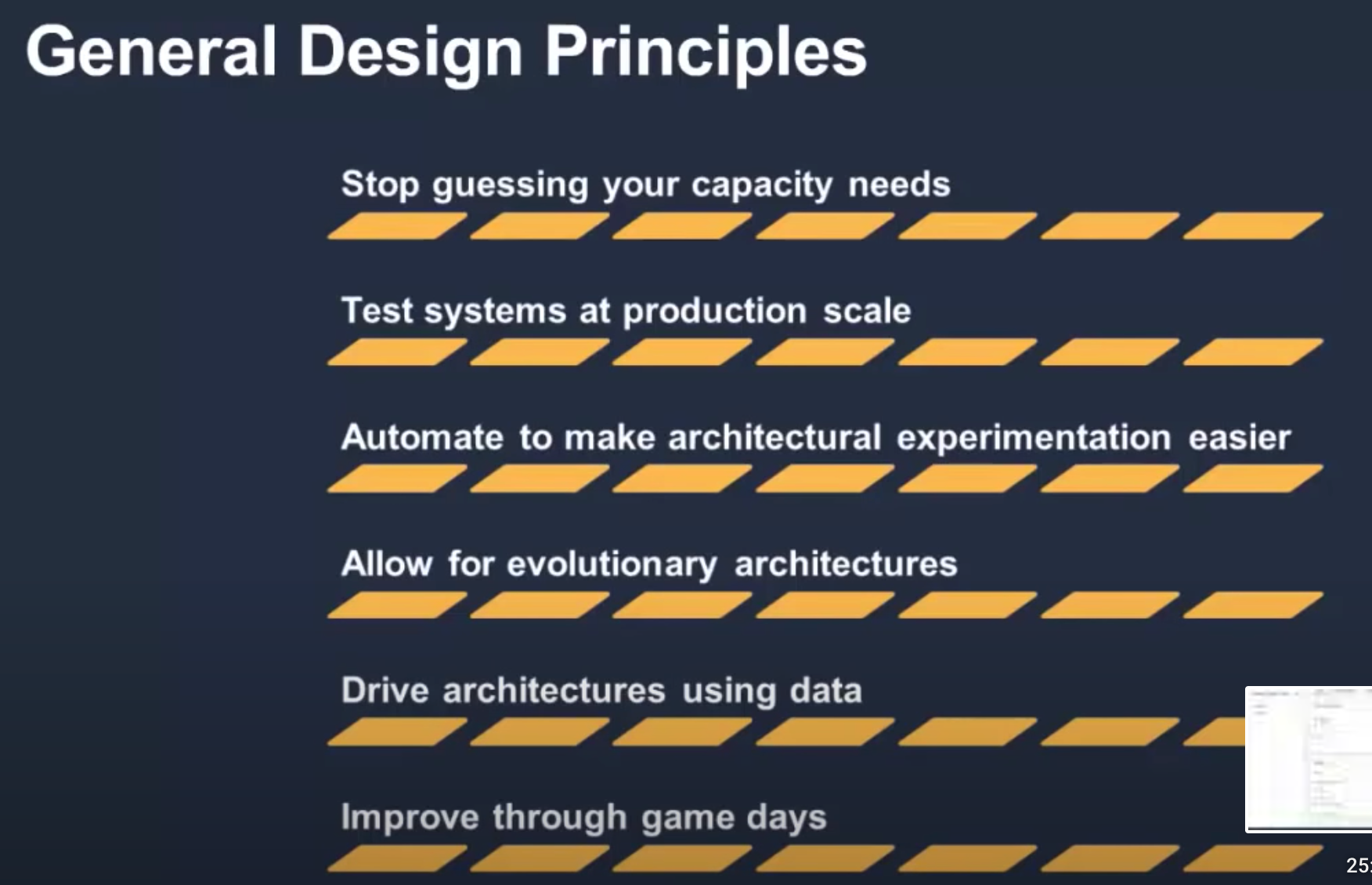
General design principles
- Stop guessing your capacity needs: If you make a poor capacity decision when deploying a workload, you might end up sitting on expensive idle resources or dealing with the performance implications of limited capacity. With cloud computing, these problems can go away. You can use as much or as little capacity as you need, and scale up and down automatically.
- Test systems at production scale: In the cloud, you can create a production-scale test environment on demand, complete your testing, and then decommission the resources. Because you only pay for the test environment when it’s running, you can simulate your live environment for a fraction of the cost of testing on premises.
- Automate to make architectural experimentation easier: Automation allows you to create and replicate your workloads at low cost and avoid the expense of manual effort. You can track changes to your automation, audit the impact, and revert to previous parameters when necessary.
- Allow for evolutionary architectures: In a traditional environment, architectural decisions are often implemented as static, onetime events, with a few major versions of a system during its lifetime. As a business and its context continue to evolve, these initial decisions might hinder the system’s ability to deliver changing business requirements. In the cloud, the capability to automate and test on demand lowers the risk of impact from design changes. This allows systems to evolve over time so that businesses can take advantage of innovations as a standard practice.
- Drive architectures using data: In the cloud, you can collect data on how your architectural choices affect the behavior of your workload. This lets you make fact-based decisions on how to improve your workload. Your cloud infrastructure is code, so you can use that data to inform your architecture choices and improvements over time.
- Improve through game days: Test how your architecture and processes perform by regularly scheduling game days to simulate events in production. This will help you understand where improvements can be made and can help develop organizational experience in dealing with events.
Operational excellence
- Perform operations as code: In the cloud, you can apply the same engineering discipline that you use for application code to your entire environment. You can define your entire workload (applications, infrastructure) as code and update it with code. You can implement your operations procedures as code and automate their execution by triggering them in response to events. By performing operations as code, you limit human error and enable consistent responses to events.
- Make frequent, small, reversible changes: Design workloads to allow components to be updated regularly. Make changes in small increments that can be reversed if they fail (without affecting customers when possible).
- Refine operations procedures frequently: As you use operations procedures, look for opportunities to improve them. As you evolve your workload, evolve your procedures appropriately. Set up regular game days to review and validate that all procedures are effective and that teams are familiar with them.
- Anticipate failure: Perform “pre-mortem” exercises to identify potential sources of failure so that they can be removed or mitigated. Test your failure scenarios and validate your understanding of their impact. Test your response procedures to ensure that they are effective, and that teams are familiar with their execution. Set up regular game days to test workloads and team responses to simulated events.
- Learn from all operational failures: Drive improvement through lessons learned from all operational events and failures. Share what is learned across teams and through the entire organization.
Security
- Implement a strong identity foundation: Implement the principle of least privilege and enforce separation of duties with appropriate authorization for each interaction with your AWS resources. Centralize identity management, and aim to eliminate reliance on long-term static credentials.
- Enable traceability: Monitor, alert, and audit actions and changes to your environment in real time. Integrate log and metric collection with systems to automatically investigate and take action.
- Apply security at all layers: Apply a defense in depth approach with multiple security controls. Apply to all layers (for example, edge of network, VPC, load balancing, every instance and compute service, operating system, application, and code).
- Automate security best practices: Automated software-based security mechanisms improve your ability to securely scale more rapidly and cost-effectively. Create secure architectures, including the implementation of controls that are defined and managed as code in version-controlled templates.
- Protect data in transit and at rest: Classify your data into sensitivity levels and use mechanisms, such as encryption, tokenization, and access control where appropriate.
- Keep people away from data: Use mechanisms and tools to reduce or eliminate the need for direct access or manual processing of data. This reduces the risk of mishandling or modification and human error when handling sensitive data.
- Prepare for security events: Prepare for an incident by having incident management and investigation policy and processes that align to your organizational requirements. Run incident response simulations and use tools with automation to increase your speed for detection, investigation, and recovery.
Reliability
- Automatically recover from failure: By monitoring a workload for key performance indicators (KPIs), you can trigger automation when a threshold is breached. These KPIs should be a measure of business value, not of the technical aspects of the operation of the service. This allows for automatic notification and tracking of failures, and for automated recovery processes that work around or repair the failure. With more sophisticated automation, it’s possible to anticipate and remediate failures before they occur.
- Test recovery procedures: In an on-premises environment, testing is often conducted to prove that the workload works in a particular scenario. Testing is not typically used to validate recovery strategies. In the cloud, you can test how your workload fails, and you can validate your recovery procedures. You can use automation to simulate different failures or to recreate scenarios that led to failures before. This approach exposes failure pathways that you can test and fix before a real failure scenario occurs, thus reducing risk.
- Scale horizontally to increase aggregate workload availability: Replace one large resource with multiple small resources to reduce the impact of a single failure on the overall workload. Distribute requests across multiple, smaller resources to ensure that they don’t share a common point of failure.
- Stop guessing capacity: A common cause of failure in on-premises workloads is resource saturation, when the demands placed on a workload exceed the capacity of that workload (this is often the objective of denial of service attacks). In the cloud, you can monitor demand and workload utilization, and automate the addition or removal of resources to maintain the optimal level to satisfy demand without over- or under-provisioning. There are still limits, but some quotas can be controlled and others can be managed (see Manage Service Quotas and Constraints).
- Manage change in automation: Changes to your infrastructure should be made using automation. The changes that need to be managed include changes to the automation, which then can be tracked and reviewed.
Performance efficiency
- Democratize advanced technologies: Make advanced technology implementation easier for your team by delegating complex tasks to your cloud vendor. Rather than asking your IT team to learn about hosting and running a new technology, consider consuming the technology as a service. For example, NoSQL databases, media transcoding, and machine learning are all technologies that require specialized expertise. In the cloud, these technologies become services that your team can consume, allowing your team to focus on product development rather than resource provisioning and management.
- Go global in minutes: Deploying your workload in multiple AWS Regions around the world allows you to provide lower latency and a better experience for your customers at minimal cost.
- Use serverless architectures: Serverless architectures remove the need for you to run and maintain physical servers for traditional compute activities. For example, serverless storage services can act as static websites (removing the need for web servers) and event services can host code. This removes the operational burden of managing physical servers, and can lower transactional costs because managed services operate at cloud scale.
- Experiment more often: With virtual and automatable resources, you can quickly carry out comparative testing using different types of instances, storage, or configurations.
- Consider mechanical sympathy: Understand how cloud services are consumed and always use the technology approach that aligns best with your workload goals. For example, consider data access patterns when you select database or storage approaches.
Cost optimization
- Implement Cloud Financial Management: To achieve financial success and accelerate business value realization in the cloud, you need to invest in Cloud Financial Management /Cost Optimization. Your organization needs to dedicate time and resources to build capability in this new domain of technology and usage management. Similar to your Security or Operational Excellence capability, you need to build capability through knowledge building, programs, resources, and processes to become a cost-efficient organization.
- Adopt a consumption model: Pay only for the computing resources that you require and increase or decrease usage depending on business requirements, not by using elaborate forecasting. For example, development and test environments are typically only used for eight hours a day during the work week. You can stop these resources when they are not in use for a potential cost savings of 75% (40 hours versus 168 hours).
- Measure overall efficiency: Measure the business output of the workload and the costs associated with delivering it. Use this measure to know the gains you make from increasing output and reducing costs.
- Stop spending money on undifferentiated heavy lifting: AWS does the heavy lifting of data center operations like racking, stacking, and powering servers. It also removes the operational burden of managing operating systems and applications with managed services. This allows you to focus on your customers and business projects rather than on IT infrastructure.
- Analyze and attribute expenditure: The cloud makes it easier to accurately identify the usage and cost of systems, which then allows transparent attribution of IT costs to individual workload owners. This helps measure return on investment (ROI) and gives workload owners an opportunity to optimize their resources and reduce costs.
Review Process
The review process describes in high-level terms, how the assessment of the principles should be done. For AWS, this should be a lightweight process, which is taking rather hours, instead of days and it should be repeated multiple times across the architecture lifecycle. AWS states that it is important to have a conversation (not an audit) and a “blame-free approach” during the review and it is also important to involve the right people. The results of the conversations should be a list of issues that can then be prioritized based on the business context and that can be formulated into a set of actions that help to improve the overall customer experience of the architecture.
Well-Architected Tool
AWS Console Tool that steps a user through the Well-Architected Review Process
Well-Architected Alternate Renditions
Consuming the WA PDFs or web content can be a bit challenging with navigation. The WA questions, resources, etc. are available as json via the AWS WA Console Tool with some scraping. This creates alternate renditions based on this data.
- Run
aws-well-architected-reformat/main.jsto generate a reformatted and condensed version of WA.cd aws-well-architected-reformat node main.js > ../aws-well-architected-condensed.md - see alternate rendition at
aws-well-architected-condensed.md - See
aws-well-architected-reformat/datafor the question data asjsonfor each lens.
Notes on pulling data via AWS Console
# aws console request format
POST https://console.aws.amazon.com/wellarchitected/api/apiservice
{"method":"GET","path":"/workloads/4cfa14fe4a9d351afc9975cfdcb434af/lensReviews/wellarchitected/answers","region":"us-east-1","headers":{"Content-Type":"application/json","Accept":"application/json"},"params":{"PillarId":"operationalExcellence","MaxResults":50,"Locale":"en"}}
# helpful Resources on right sidebar example
https://wa.aws.amazon.com/TypeII/en/foundationaltechnicalreview/foundationaltechnicalreview.sec_q1.helpful-resources.en.html
Feature Request
Custom lenses have been added. See Custom lenses
One area where there is a gap for an enterprises are all the company specific policies, standards, and best practices that are additive and need to be addressed on top of AWS. These types of questions and guidance would need to happen outside of WA Tool.
A feature to define custom lenses - a customer defined lens. This way the single WA Tool could be the method for review facilitation, improvement reporting and maintaining history.
Custom Lens
template JSON file for creating custom lens
{
"schemaVersion": "2021-11-01",
"name": "Replace with lens name",
"description": "Replace with your description",
"pillars": [
{
"id": "pillar_id_1",
"name": "Pillar 1",
"questions": [
{
"id": "pillar_1_q1",
"title": "My first question",
"description": "Description isn't a necessary property here for a question, but it might help your lens users.",
"choices": [
{
"id": "choice1",
"title": "Best practice #1",
"helpfulResource": {
"displayText": "It's recommended that you include a helpful resource text and URL for each choice for your users.",
"url": "https://aws.amazon.com"
},
"improvementPlan": {
"displayText": "You must have improvement plans per choice. It's optional whether or not to have a corresponding URL."
}
},
{
"id": "choice2",
"title": "Best practice #2",
"helpfulResource": {
"displayText": "It's recommended that you include a helpful resource text and URL for each choice for your users.",
"url": "https://aws.amazon.com"
},
"improvementPlan": {
"displayText": "You must have improvement plans per choice. It's optional whether or not to have a corresponding URL."
}
}
],
"riskRules": [
{ "condition": "choice1 && choice2", "risk": "NO_RISK" },
{ "condition": "choice1 && !choice2", "risk": "MEDIUM_RISK" },
{ "condition": "default", "risk": "HIGH_RISK" }
]
}
]
}
]
}
Key Visuals


Resources
- AWS Well-Architected
- Documentation | AWS Well-Architected Framework
- The Review Process - AWS Well-Architected Framework
- AWS Well Architected framework: A Complete Checklist
- AWS Well-Architected Framework Cheatsheet | Cloud Noon
- AWS Well-Architected Tool: Custom lenses
- Announcing AWS Well-Architected Custom Lenses: Extend the Well-Architected Framework with Your Internal Best Practices
- Customize Well-Architected Reviews using Custom Lenses and the AWS Well-Architected Tool
- Custom lenses