EMR Serverless
code for article pfeilbr/emr-serverless-playground
learn EMR Serverless
provides a serverless runtime environment that simplifies the operation of analytics applications that use the latest open source frameworks, such as Apache Spark and Apache Hive. With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks.
general flow
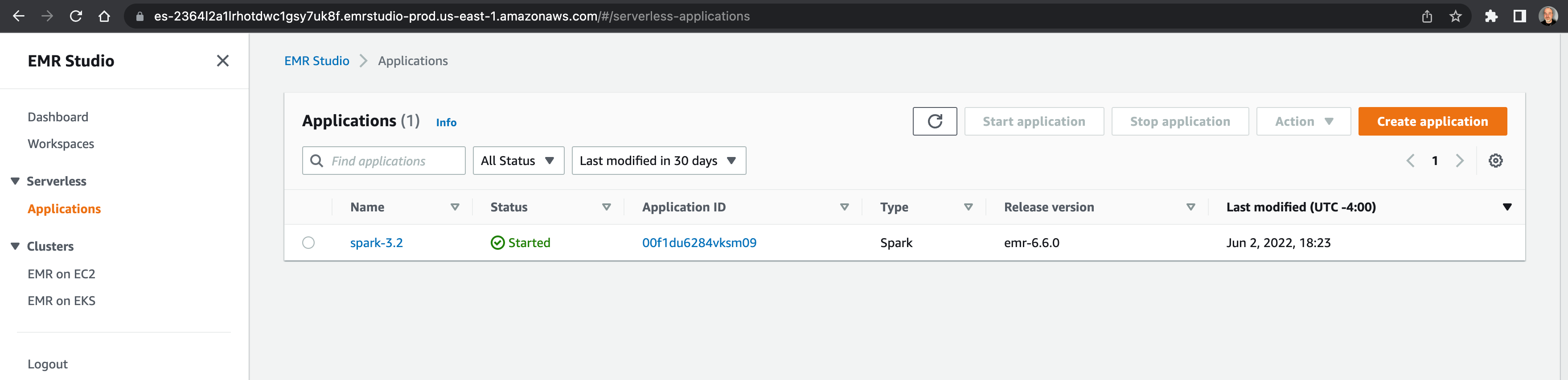
- create application
- start application
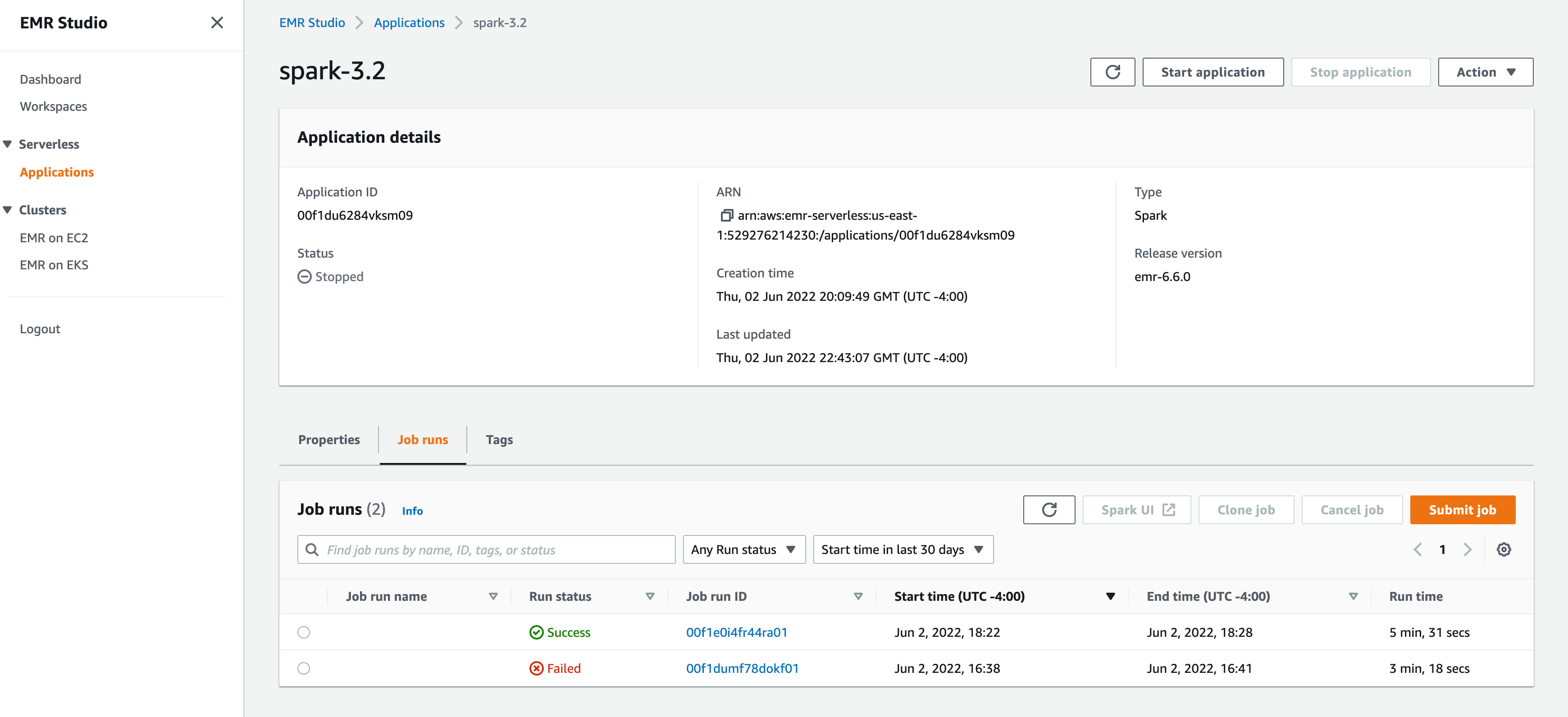
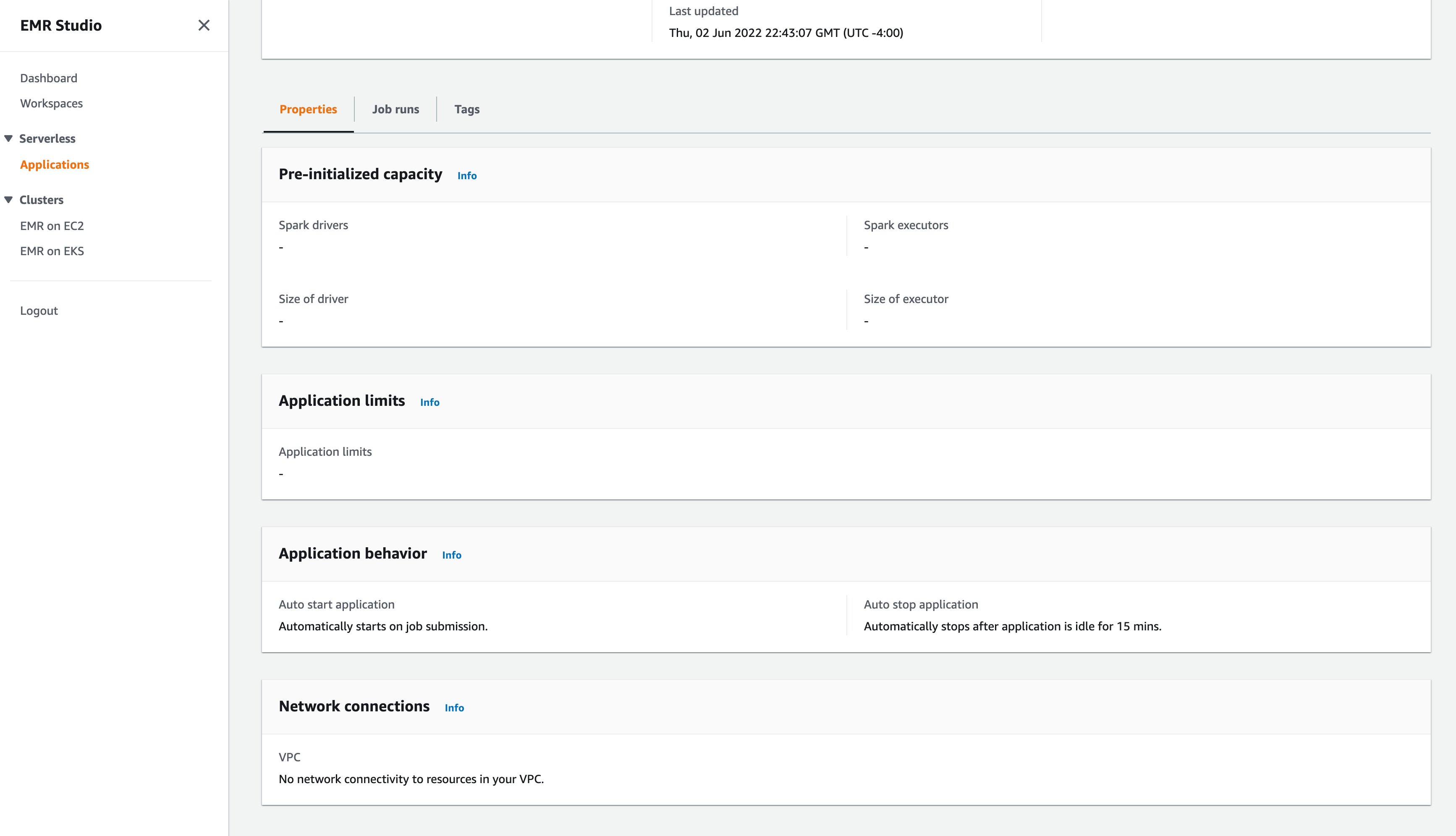
your application is setup to start with pre-initialized capacity of 1 Spark driver and 1 Spark executor. Your application is by default configured to start when jobs are submitted and stop when the application is idle for more than 15 minutes.
- submit application jobs. e.g. spark or hive
Demo
# deploy template.yaml
sam deploy --guided
aws emr-serverless get-application \
--application-id 00f1du6284vksm09
{
"application": {
"applicationId": "00f1du6284vksm09",
"name": "spark-3.2",
"arn": "arn:aws:emr-serverless:us-east-1:529276214230:/applications/00f1du6284vksm09",
"releaseLabel": "emr-6.6.0",
"type": "Spark",
"state": "CREATED",
"stateDetails": "",
"createdAt": "2022-06-02T20:09:49.041000+00:00",
"updatedAt": "2022-06-02T20:09:49.667000+00:00",
"tags": {
"tag-on-create-key": "tag-on-create-value"
},
"autoStartConfiguration": {
"enabled": true
},
"autoStopConfiguration": {
"enabled": true,
"idleTimeoutMinutes": 15
}
}
}
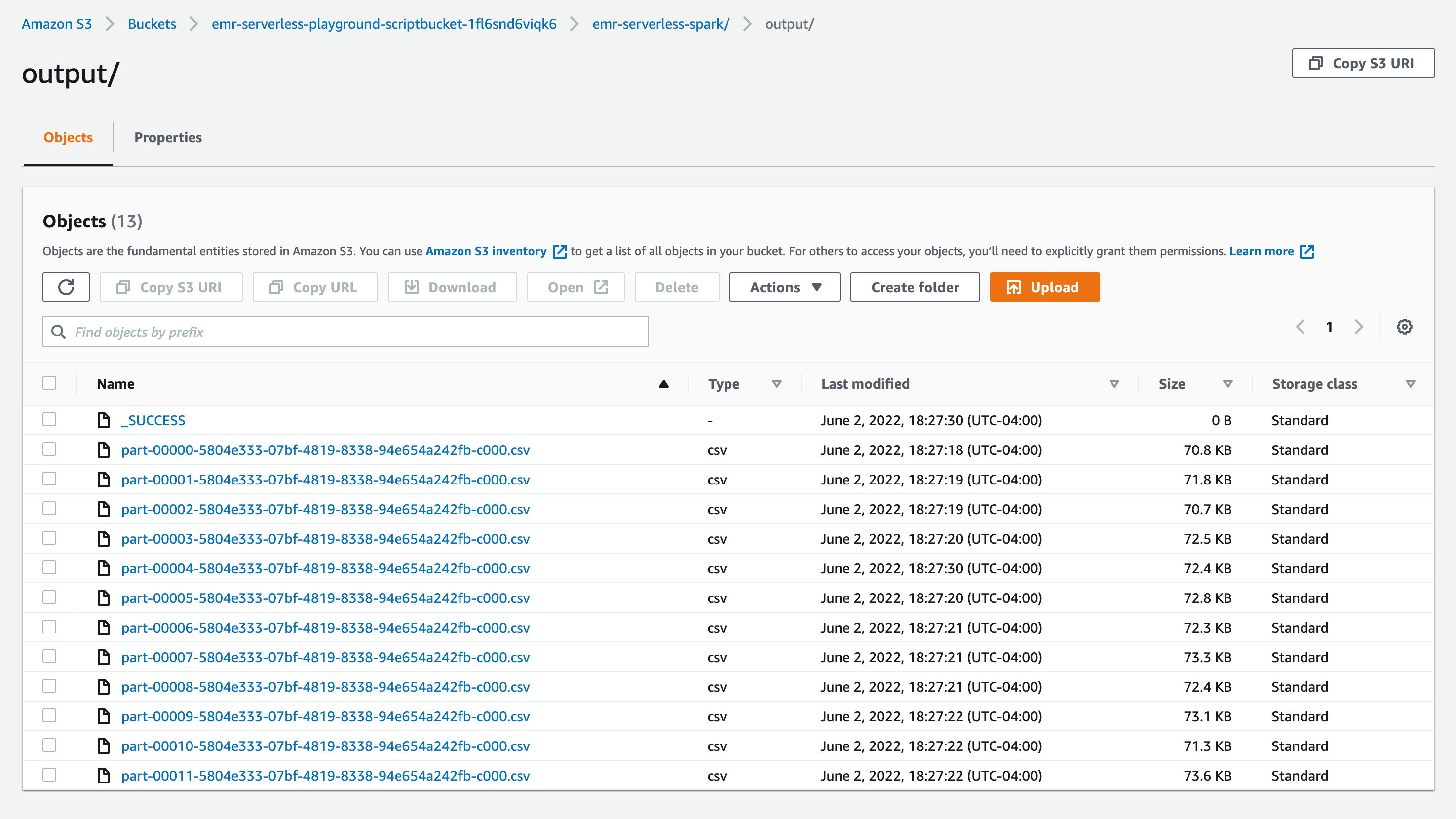
aws s3 cp s3://us-east-1.elasticmapreduce/emr-containers/samples/wordcount/scripts/wordcount.py s3://emr-serverless-playground-scriptbucket-1fl6snd6viqk6/scripts/
APPLICATION_ID="00f1du6284vksm09"
EXECUTION_ROLE_ARN="arn:aws:iam::529276214230:role/EMRServerless_Job_Execution_Role"
BUCKET_NAME="emr-serverless-playground-scriptbucket-1fl6snd6viqk6"
aws emr-serverless start-job-run \
--application-id $APPLICATION_ID \
--execution-role-arn $EXECUTION_ROLE_ARN \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://emr-serverless-playground-scriptbucket-1fl6snd6viqk6/scripts/wordcount.py",
"entryPointArguments": ["s3://emr-serverless-playground-scriptbucket-1fl6snd6viqk6/emr-serverless-spark/output"],
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
}'
# output
{
"applicationId": "00f1du6284vksm09",
"jobRunId": "00f1e0i4fr44ra01",
"arn": "arn:aws:emr-serverless:us-east-1:529276214230:/applications/00f1du6284vksm09/jobruns/00f1e0i4fr44ra01"
}
JOB_RUN_ID="00f1e0i4fr44ra01"
aws emr-serverless get-job-run \
--application-id $APPLICATION_ID \
--job-run-id $JOB_RUN_ID
# output
{
"jobRun": {
"applicationId": "00f1du6284vksm09",
"jobRunId": "00f1e0i4fr44ra01",
"arn": "arn:aws:emr-serverless:us-east-1:529276214230:/applications/00f1du6284vksm09/jobruns/00f1e0i4fr44ra01",
"createdBy": "arn:aws:sts::529276214230:assumed-role/AWSReservedSSO_AWSAdministratorAccess_af1bdd24238208b5/pfeilbr",
"createdAt": "2022-06-02T22:22:36.221000+00:00",
"updatedAt": "2022-06-02T22:28:06.614000+00:00",
"executionRole": "arn:aws:iam::529276214230:role/EMRServerless_Job_Execution_Role",
"state": "SUCCESS",
"stateDetails": "",
"releaseLabel": "emr-6.6.0",
"jobDriver": {
"sparkSubmit": {
"entryPoint": "s3://emr-serverless-playground-scriptbucket-1fl6snd6viqk6/scripts/wordcount.py",
"entryPointArguments": [
"s3://emr-serverless-playground-scriptbucket-1fl6snd6viqk6/emr-serverless-spark/output"
],
"sparkSubmitParameters": "--conf spark.executor.cores=1 --conf spark.executor.memory=4g --conf spark.driver.cores=1 --conf spark.driver.memory=4g --conf spark.executor.instances=1"
}
},
"tags": {},
"totalResourceUtilization": {
"vCPUHour": 0.066,
"memoryGBHour": 0.331,
"storageGBHour": 1.322
}
}
}
JOB_RUN_LOGS="s3://$BUCKET_NAME/emr-serverless-spark/logs/applications/$APPLICATION_ID/jobs/$JOB_RUN_ID"
Notes
- unlike EMR the EC2 instances backing EMR-Serverless applications/jobs are not visible to the customer / fully managed (e.g. not visible in the customer EC2 console)
- Type - Spark or HIVE
- ReleaseLabel - EMR release version associated with the application. see Release versions
- EMR Serverless is a Regional service
- Job run states
- Spark examples
- Hive job examples
- Using Python libraries with EMR Serverless
- Submitting jobs from Airflow
Resource Types
- application -
arn:${Partition}:emr-serverless:${Region}:${Account}:/applications/${ApplicationId} - jobRun
arn:${Partition}:emr-serverless:${Region}:${Account}:/applications/${ApplicationId}/jobruns/${JobRunId}
AWS CLI Support
# create application
aws emr-serverless create-application \
--type HIVE \
--name serverless-demo \
--release-label "emr-6.6.0" \
--initial-capacity '{
"DRIVER": {
"workerCount": 1,
"resourceConfiguration": {
"cpu": "2vCPU",
"memory": "4GB",
"disk": "30gb"
}
},
"TEZ_TASK": {
"workerCount": 10,
"resourceConfiguration": {
"cpu": "4vCPU",
"memory": "8GB",
"disk": "30gb"
}
}
}' \
--maximum-capacity '{
"cpu": "400vCPU",
"memory": "1024GB",
"disk": "1000GB"
}'
# start application
# your application is setup to start with pre-initialized capacity of 1 Spark driver and 1 Spark executor. Your application is by default configured to start when jobs are submitted and stop when the application is idle for more than 15 minutes.
aws emr-serverless start-application \
--application-id $APPLICATION_ID
# submit hive job
aws emr-serverless start-job-run \
--application-id $APPLICATION_ID \
--execution-role-arn $JOB_ROLE_ARN \
--job-driver '{
"hive": {
"initQueryFile": "s3://'${S3_BUCKET}'/code/hive/create_table.sql",
"query": "s3://'${S3_BUCKET}'/code/hive/extreme_weather.sql",
"parameters": "--hiveconf hive.exec.scratchdir=s3://'${S3_BUCKET}'/hive/scratch --hiveconf hive.metastore.warehouse.dir=s3://'${S3_BUCKET}'/hive/warehouse"
}
}' \
--configuration-overrides '{
"applicationConfiguration": [
{
"classification": "hive-site",
"properties": {
"hive.driver.cores": "2",
"hive.driver.memory": "4g",
"hive.tez.container.size": "8192",
"hive.tez.cpu.vcores": "4"
}
}
],
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://'${S3_BUCKET}'/hive-logs/"
}
}
}'
CloudFormation Support
AWS::EMRServerless::Application
example AWS::EMRServerless::Application usage in cfn
- https://github.com/aws-samples/emr-serverless-samples/blob/main/cloudformation/emr_serverless_spark_app.yaml#L6
- https://github.com/aws-samples/emr-serverless-samples/blob/main/cloudformation/emr_serverless_full_deployment.yaml#L61
AWS Console Screenshots